Restez toujours informé: suivez-nous sur Google Actualités (icone ☆)
Un Algorithme pour déterminer l'orientation des objets pourrait aider les robots à comprendre leur environnement et ainsi s'orienter.
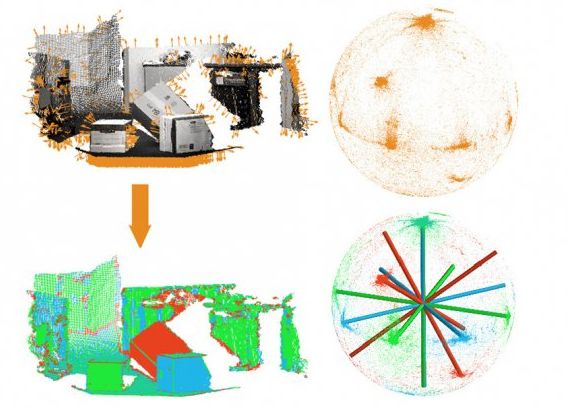
La première étape de l'algorithme consiste à estimer les orientations des différents points de la scène (flèches oranges), dont il les fait correspondre à la surface d'une sphère (clusters d'orange). Par un processus itératif, il trouve l'ensemble des axes qui correspondent le mieux, les grappes de points (rouge, bleu, vert et colonnes), qu'il ré-identifie avec les points de la scène. Illustration: MIT
Supposons que vous vous déplaciez dans un quartier inconnu d'une grande ville, et que vous utilisiez un groupe particulier de gratte-ciel comme un point de référence. Le sens de la circulation et les rues à sens unique vous obligent à faire des détours et à vous éloigner jusqu'à perdre de vue vos repères. Quand ils réapparaissent, afin de les utiliser pour vous repérer vous devez être en mesure de les identifier de nouveau comme les mêmes bâtiments que vous utilisiez comme repère avant et déterminer votre orientation par rapport à eux.
Ce type de ré-identification est une seconde nature pour l'homme, mais il est difficile pour les ordinateurs. Lors de la conférence IEEE sur la vision par ordinateur et reconnaissance de formes en Juin, les chercheurs du MIT présenteront un nouvel algorithme qui pourrait rendre beaucoup plus facile ce repérage, en identifiant les grandes orientations d'objets dans les scènes en 3D. Le même algorithme pourrait aussi simplifier le problème de la compréhension de la scène, l'un des principaux défis de la recherche en vision par ordinateur.
La première étape de l'algorithme consiste à estimer les orientations des différents points de la scène (flèches oranges), dont il les fait correspondre à la surface d'une sphère (clusters d'orange). Par un processus itératif, il trouve l'ensemble des axes qui correspondent le mieux, les grappes de points (rouge, bleu, vert et colonnes), qu'il ré-identifie avec les points de la scène.
L'algorithme est principalement destiné à aider les robots à se déplacer dans des bâtiments inconnus, comme les automobilistes circulant dans des villes inconnues, le principe est le même. Il fonctionne en identifiant les orientations d'objets dominants dans une scène donnée, qu'il représente comme des ensembles d'axes, appelés "cadres Manhattan", inclus dans une sphère. Quand un robot se déplace, il observe les lieux dans toutes les directions, et peut mesurer son orientation par rapport aux axes. Chaque fois qu'il se réoriente, il détermine les images en 3D de ses points de repère qui devraient être orientés vers lui, ce qui les rend beaucoup plus faciles à identifier.
Julian Straub, un étudiant diplômé en génie électrique et informatique au MIT, est l'auteur principal de l'article. Il est rejoint par ses conseillers, John Fisher, directeur de recherche en informatique du MIT et Laboratoire d'intelligence artificielle, et John Leonard, un professeur de génie mécanique et de l'océan, ainsi que Oren Freifeld et Guy Rosman, deux post-doctorants.
Un nouvel algorithme
Les chercheurs travaillent sur des données 3-D du type de celles analysées par le capteur Kinect de Microsoft et des télémètres laser. Tout d'abord, en utilisant des procédures établies, l'algorithme estime les orientations d'un grand nombre de points individuels de la scène. Ces orientations sont ensuite représentées par des points sur la surface d'une sphère, chaque point définissant un angle unique par rapport au centre de la sphère.
Les points de la sphère forment des grappes lâches qui peuvent être difficiles à distinguer. On utilise des informations statistiques sur l'incertitude des estimations initiale d'orientation, l'algorithme tente alors de s'adapter à des cadres de Manhattan aux points de la sphère.

L'algorithme prend les informations de profondeur (rouge) sur une scène visuelle Illustration: MIT
L'idée de base est similaire à celle de l'analyse de régression, trouver les lignes de corrélation entre des points dispersés. Mais la géométrie de la sphère complique les calculs "La plupart des statistiques classiques sont basées sur la linéarité et la distance euclidienne, donc vous pouvez prendre deux points, vous pouvez les additionner, diviser par deux, et cela vous donnera la moyenne", déclare Freifeld. "Mais lorsque vous travaillez dans des espaces qui sont non linéaires, quand vous faites la moyenne, vous pouvez tomber en dehors de l'espace."
Considérons, par exemple, l'exemple de mesurer les distances géographiques. "Dites que vous êtes à Tokyo et que je suis à New York," dit Freifeld. "Nous ne voulons pas que nos calculs nous situent au centre de la terre; nous voulons que le résultat soit sur la surface. "Une des clés du nouvel algorithme est le fait qu'il intègre ces géométries dans le raisonnement statistique sur la scène.
En principe, il serait possible de rapprocher les données de points très précisément à l'aide de centaines de différents cadres de Manhattan, mais que donnerait un modèle qui est beaucoup trop complexe pour être utile. Donc, un autre aspect de l'algorithme est une fonction de valeur qui affine la précision de l'approximation par rapport au nombre de trames. L'algorithme commence par un nombre fixe d'images entre trois et dix, selon la complexité de la scène attendue et ensuite essaie de diminuer ce nombre sans compromettre la fonction de la valeur globale.
L'ensemble de trames de Manhattan résultant peut ne pas représenter des distinctions subtiles entre des objets qui sont légèrement mal alignés avec l'autre, mais ces différences ne sont pas très utiles pour un système de navigation. "Pensez à la façon dont vous vous déplacez dans une chambre", dit Fisher. "Vous n'avez pas mémorisé un modèle précis de votre environnement. C'est un modèle de capture statistique lâche qui vous permet de vous déplacer de manière à ne pas tomber sur une chaise ou un autre objet."

L'algorithme prend les informations de profondeur (rouge) sur une scène visuelle et détermine l'orientation des objets représentés (rouge, bleu et vert). Cela permet une résolution de la profondeur beaucoup plus simple (plusieurs couleurs). Illustration: MI
Une fois qu'un ensemble de trames de Manhattan a été déterminé, le problème du plan de segmentation devient beaucoup plus facile. Les objets qui ne prennent pas beaucoup de place dans le champ visuel, parce qu'ils sont petits ou distants, sont exclus des algorithmes du plan de segmentation, parce qu'ils produisent si peu d'informations de profondeur que leurs orientations ne peuvent pas en être déduites de manière fiable. Le problème est celui de la sélection parmi quelques orientations possibles, plutôt que d'une infinité de sélections potentielles.
Frank Dellaert, professeur de l'informatique interactive à Georgia Tech qui n'était pas impliqué dans cette recherche, trouve le travail "intéressant", il fonctionne avec des images en 3d, qui sont devenues courantes avec la diffusion grand public de Kinect et d'autres capteurs de profondeur. "Je crois que des techniques telles que celles-ci doivent être appliquées", notamment dans la mise en œuvre des systèmes autonomes fabriqués en série, tel des robots ménagers ou des véhicules totalement autonomes.
Populaires