Restez toujours informé: suivez-nous sur Google Actualités (icone ☆)
Après avoir utilisé la technologie OCR (Optical Character Recognition) pour permettre aux internautes de rechercher du texte dans un livre numérisé, Google intègre désormais cet outil dans Google Docs. Cette option, qui était en test depuis Septembre 2009, permet aux utilisateurs d'extraire le texte présent sur une image (JPG, GIF ou PNG) ou sur un fichier PDF.
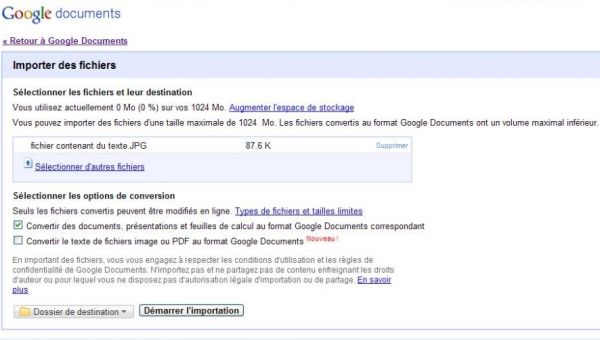
Google intègre la reconnaissance optique de caractère dans Google Docs
Illustration: Extrait Google Documents
Pour le moment, les langues reconnues sont l'anglais, espagnol, italien, français et allemand. Son utilisation est simple: lors de l'importation d'un fichier, cette nouvelle option apparaît: "Convertir le texte de fichiers image ou PDF au format Google Documents". En la cochant, ce n'est pas le document lui-même qui sera importé, mais le texte qu'il contient. Ce document aura les mêmes options qu'un document texte classique, il pourra par exemple être traduit.
Google l'admet, le résultat n'est pas parfait. De nombreuses erreurs peuvent être rencontrées, le formatage initial est rarement conservé. L'OCR fonctionne apparemment mieux avec des images en haute résolution.
Auteur de l'article: Cédric DEPOND
Populaires