Compress. images
1 - Introduction2 - Le codage binaire, hexa, ascii et les images numériques3 - Canon à électrons, images et couleurs4 - Introduction à la compression5 - Sans perte: méthodes basées sur les répétitions6 - Sans perte: méthodes de type dictionnaire7 - Sans perte: méthodes statistiques8 - Avec perte: la compression JPEG9 - Avec perte: la compression fractale10 - Avec perte: la compression par ondelettes11 - Conclusion
1 - Introduction
La compression numérique des images se trouve partout, et pour cause: sans compression, Internet ne serait pas ce qu'il est. Mais comment est-il possible de réduire considérablement la taille mémoire des images tout en gardant une grande qualité d'affichage ?
Les auteurs de ce dossier sont Christophe RINGLER et Gilles WENTZ, un grand merci à eux. Plus de renseignements sur les auteurs sont disponibles sur leur site: lien
Ainsi, on préfère réduire la taille des données en exploitant la puissance des processeurs plutôt que d'augmenter les capacités de stockage et de télécommunication.
Pour utiliser les images numériques, il faut comprimer les fichiers dans lesquels elles sont enregistrées. Voici comment on y parvient, sans les dénaturer. L'image, bien plus que le son, consomme une quantité impressionnante d'octets quand elle est numérisée. Pour s'en rendre compte, deux exemples suffisent. Aujourd'hui, on parle de " qualité megapixel " pour les appareils photo numériques; cela signifie que chaque image comporte environ un million de pixels, chaque pixel nécessitant trois octets pour les composantes RVB (rouge, vert, bleu). Sans compression, cela représenterait un peu plus de 3 Mo pour une seule photographie. L'équivalent d'une pellicule de trente-six poses occuperait ainsi 100 Mo !
Pour remédier à ces contraintes, il n'y a qu'une solution: comprimer les images. Les chercheurs ont imaginé de nombreuses méthodes de compression, que l'on classe en deux catégories: celles qui se contentent de comprimer les données sans les altérer, et celles qui les compactent en les modifiant. Les premières, dites non destructives, permettent de reconstituer, au bit près, le fichier dans l'état où il était avant la compression (ce qui est indispensable pour du texte).
Les auteurs de ce dossier sont Christophe RINGLER et Gilles WENTZ, un grand merci à eux. Plus de renseignements sur les auteurs sont disponibles sur leur site: lien
Introduction
De nos jours, la puissance des processeurs augmente plus vite que les capacités de stockage, et énormément plus vite que la bande passante d'Internet, qui, malgré les nouvelles technologies, a du mal à augmenter car cela demande d'énormes changements dans les infrastructures telles que les installations téléphoniques.Ainsi, on préfère réduire la taille des données en exploitant la puissance des processeurs plutôt que d'augmenter les capacités de stockage et de télécommunication.
Pour utiliser les images numériques, il faut comprimer les fichiers dans lesquels elles sont enregistrées. Voici comment on y parvient, sans les dénaturer. L'image, bien plus que le son, consomme une quantité impressionnante d'octets quand elle est numérisée. Pour s'en rendre compte, deux exemples suffisent. Aujourd'hui, on parle de " qualité megapixel " pour les appareils photo numériques; cela signifie que chaque image comporte environ un million de pixels, chaque pixel nécessitant trois octets pour les composantes RVB (rouge, vert, bleu). Sans compression, cela représenterait un peu plus de 3 Mo pour une seule photographie. L'équivalent d'une pellicule de trente-six poses occuperait ainsi 100 Mo !
Pour remédier à ces contraintes, il n'y a qu'une solution: comprimer les images. Les chercheurs ont imaginé de nombreuses méthodes de compression, que l'on classe en deux catégories: celles qui se contentent de comprimer les données sans les altérer, et celles qui les compactent en les modifiant. Les premières, dites non destructives, permettent de reconstituer, au bit près, le fichier dans l'état où il était avant la compression (ce qui est indispensable pour du texte).
2 - Le codage binaire, hexa, ascii et les images numériques
Le codage binaire, hexadécimale et ascii
Le binaire
Vers la fin des années 30, Claude Shannon démontra qu'à l'aide de "contacteurs" (interrupteurs) fermés pour "vrai" et ouverts pour "faux" on pouvait effectuer des opérations logiques en associant le nombre " 1 " pour "vrai" et "0" pour "faux". Ce langage est nommé langage binaire. C'est avec ce langage que fonctionnent les ordinateurs. Il permet d'utiliser deux chiffres (0 et 1) pour faire des nombres. L'homme travaille quant à lui avec 10 chiffres (0,1,2,3,4,5,6,7,8,9), on parle alors de base décimale.Le bit
Bit signifie "binary digit", c'est-à-dire 0 ou 1 en numérotation binaire. C'est la plus petite unité d'information manipulable par une machine.On peut les représenter physiquement:
- par une impulsion électrique, qui, lorsqu'elle atteint une certaine valeur, correspond à la valeur 1.
- par des trous dans une surface.
- grâce à des bistables, c'est-à-dire des composants qui ont deux états d'équilibre (un correspond à l'état 1, l'autre à 0).
Le nombre d'état possible varie en fonction du nombre de bit
Avec un bit on peut avoir soit 1, soit 0.
Avec 3 bits on peut avoir huit états différents (2*2*2 ou 2^3):

Avec huit bits on a 2^8 ou 2*2*2*2*2*2*2*2=256 possibilités, c'est ce que l'on appelle un octet.
Voici le tableau des 40 premiers états binaire possibles avec entre parenthèse les correspondant en décimale:
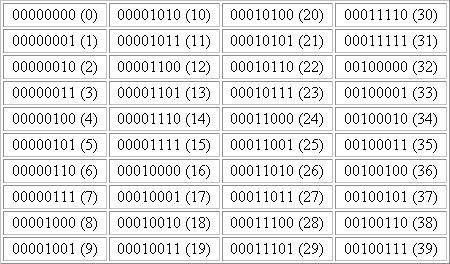
Cette notion peut être étendue à n bits, on a alors 2^n possibilités.
L'octet
L'octet est une unité d'information composée de 8 bits. Il permet de stocker un caractère, telle qu'une lettre, un chiffre.Ce regroupement de nombres par série de 8 permet une lisibilité plus grande, au même titre que l'on apprécie, en base décimale, de regrouper les nombres par trois pour pouvoir distinguer les milliers. Par exemple le nombre 1 256 245 est plus lisible que 1256245.Remarque
Une unité d'information composée de 16 bits est généralement appelée mot (en anglais word)
Une unité d'information de 32 bits de longueur est appelée double mot (en anglais double word, d'où l'appelation dword).
La base hexadécimale
Les nombres binaires étant de plus en plus longs, il a fallu introduire une nouvelle base: la base hexadécimale. La base hexadécimale consiste à compter sur une base 16, c'est pourquoi au-delà des 10 premiers chiffres on a décidé d'ajouter les 6 premières lettres: A,B,C,D,E,F.).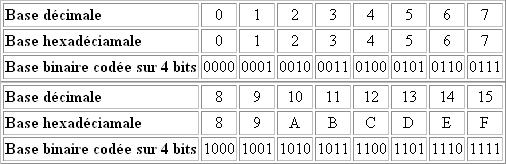
Le code ascii
La mémoire de l'ordinateur conserve toutes les données sous forme numérique. Il n'existe pas de méthode pour stocker directement les caractères. Chaque caractère possède donc son équivalent en code numérique: c'est le code ASCII (American Standard Code for Information Interchange - traduisez " Code American Standard pour l'Echange d'Informations"). Le code ASCII de base représentait les caractères sur 7 bits (c'est-à-dire 128 caractères possibles, de 0 à 127). Le code ASCII a été mis au point pour la langue anglaise, il ne contient donc pas de caractères accentués, ni de caractères spécifiques à une langue. Pour coder ce type de caractère il faut recourir à un autre code. Le code ASCII a donc été étendu à 8 bits (un octet) pour pouvoir coder plus de caractères (on parle d'ailleurs de code ASCII étendu...). Ce code attribue les valeurs 0 à 255 aux lettres majuscules et minuscules, aux chiffres, aux marques de ponctuation et aux autres symboles (caractères accentués dans le cas du code iso-latin1).Les images numériques
Les images numériques peuvent être séparées en deux grandes familles: les images numérisées d'origine extérieure et les images de synthèse (produites sur un ordinateur). Les images sont décomposées géométriquement en petites surfaces élémentaires, les pixels (contraction des mots anglais picture et element). Chaque pixel est alors défini par ses abscisses et ordonnées. Le stockage de l'image en mémoire est réalisé en conservant les données attachées à chaque pixel dans un tableau ou matrice (à chaque pixel correspondra une case de la matrice).Une image colorée est toujours le mélange de trois images de couleurs données, donc le mélange de trois images monochromes. Ces couleurs dites primaires sont indépendantes entre elles. Les terminaux des systèmes multimédia (caméras, récepteurs) utilisent les couleurs primaires: rouge, vert et bleu. L'imprimerie utilise le jaune, magenta et cyan. Ces trois couleurs sont nécessaires pour restituer l'ensemble des couleurs observables par le système visuel humain (elles forment un espace vectoriel de dimension trois).
Une représentation classique est celle qui consiste à matérialiser les trois couleurs selon trois axes dont les directions matérialisent leurs teintes (R, V, B dans notre cas) et de représenter la couleur d'un point p d'une image par un vecteur Cp, obtenu par combinaison linéaire (mélange) des quantités de couleur.
Représentation vectorielle de la couleur d'un point:
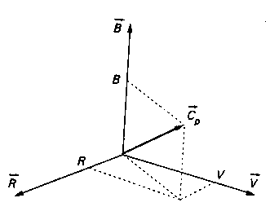
L'écriture algébrique équivalente est:
Pour les images couleurs, la valeur d'un pixel est codée par des informations sur la chrominance (paramètres I et Q) et sur la luminance (paramètre Y). Chacun des paramètres Y, I, Q est codé sur 8 bits ce qui fait un total de 24 bits nécessaire au codage d'un pixel d'une image en couleur. Dans de nombreuses applications le nombre de teintes possibles pour chaque primaire est de 256. Par combinaison linéaire on peut alors réaliser environ 16 millions de couleurs différentes.
Exemple
Calculons le nombre de digits binaires associés à une image fixe en couleur, image de télévision par exemple. On précise les paramètres suivants:
- primaires: Y, I, Q
- taille de la primaire Y: 720 points par ligne, 576 lignes
- taille des primaires I et Q: 360 points par ligne (notre acuité visuelle est de moitié dans I et Q par rapport à celle que l'on a dans Y) ; 576 lignes
- nombre de niveaux de quantification de ces primaires: 256
nombre de digits binaires = 720 x 576 x 8 + 2 x 360 x 576 x 8 = 6.63 . 106
3 - Canon à électrons, images et couleurs
Le canon à électrons
Principe
Avant de commencer l'étude de la compression des images numériques, il paraît intéressant d'étudier comment une image numérique peut se former à l'écran, ce qui suit se propose donc d'expliquer simplement le fonctionnement d'un écran à tube cathodique.Le signal-image entrant est composé de trois signaux correspondants aux trois couleurs fondamentales: rouge, bleu et vert.
Ces trois signaux pénètrent dans le tube-image, le coeur de l'écran. A l'arrière du tube-image se trouvent trois canons à électrons: un canon pour le signal de la couleur rouge, un autre pour le signal de la couleur bleue, et un troisième canon pour le signal de la couleur verte.
Le signal électrique de la couleur rouge actionne son canon à électrons. Aussitôt, des électrons sont projetés vers l'avant du tube-image, c'est à dire vers l'écran.
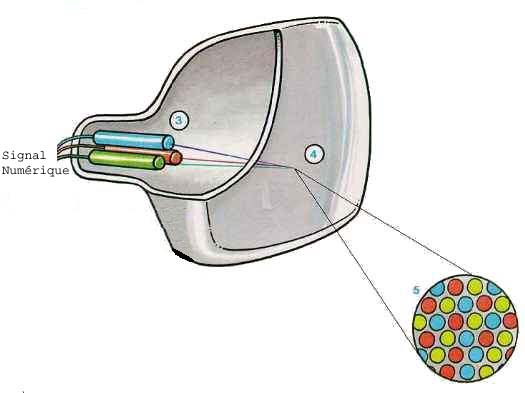
L'intérieur de l'écran est recouvert d'une multitude de minuscules points luminescents. Ces points sont groupés par trois: un rouge, un vert et un bleu. Quand les électrons du canon rouge atteignent un point rouge, celui-ci s'illumine. Les points verts réagissent aux électrons du canon vert, et les points bleus aux électrons du canon bleu. Le mariage de tous ces points verts, rouges et bleus donne l'image couleur que l'on peut observer. Si l'on examine un téléviseur avec une loupe, nous verrons que l'image est formée de milliers de points (voir schéma ci-dessous).
Principe de fonctionnement très simplifié d'un écran à tube cathodique:
Explications
Le "moteur" principal de la formation de l'image à l'écran est donc le canon à électrons. Il s'agit d'un dispositif qui émet et accélère les électrons.Il peut être schématisé ainsi:
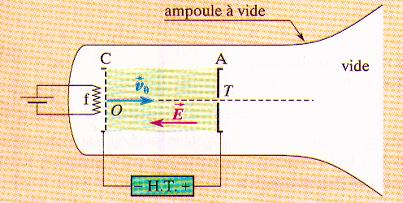
Le canon à électrons est composé de:
- Une plaque métallique C, appelée cathode, émettrice d'électrons par chauffage électrique de façon à accélérer l'énergie cinétique des électrons jusqu'à les expulser.
- Une plaque métallique A, l'anode, qui attire les électrons émis par C. Elle est percée d'un trou T d'où sortirons les électrons. Cet ensemble est fermé dans un tube à l'intérieur duquel est réalisé un vide très poussé.
A est reliée à la borne positive d'un générateur de tension et C à la borne négative. La tension Uac peut atteindre quelques dizaines de kilovolts.
Les plaques A et C étant parallèles, on peut assimiler le champ électrique entre celles-ci à un champ uniforme, de valeur E=Uac/d, d étant la distance entre l'anode et la catthode. Sa direction est celle de OT et son sens, de A vers C, c'est à dire d la plaque chargée positivement vers la plaque chargée négativement (sens des potentiels décroissants: Uac= Va-Vc>0, donc Vc
Cette accélération d'électrons n'est que la première étape de la constitution de l'image sur l'écran. Après être sorti du premier champ électrique les électrons entrent dans un second dispositif destiné à les faire dévier de façon à pouvoir afficher une image sur plusieurs lignes et non pas une seule (si les électrons ne sont pas déviés).
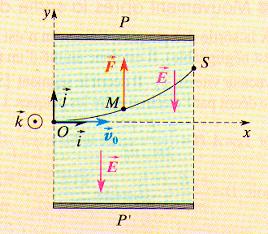
Le dispositif de déviation (voir schéma ci-dessous) est constitué par deux plaques P et P' parallèles et horizontales entre lesquelles est appliquée une tension électrique constante Upp' positive. Les électrons, lancés avec la vitesse v acquise à la sortie du canon arrivent suivant l'axe x du dispositif. Le champ électrique est uniforme entre ces plaques. L'électron est soumis à la force verticale F=-e.E (e étant la charge de l'électron et E le vecteur du champ électrique). Les électrons sont déviés soit vers le haut (F et E sont colinéaires et de sens contraires), soit vers le bas (si F et E sont colinéaires et de même sens) suivant une trajectoire parabolique.
C'est grâce à ce dispositif que le canon à électrons permet de balayer chaque ligne de l'écran successivement et d'afficher une image à partir d'un signal numérique.
Images et couleurs
Comme toute donnée informatique, une image numérique est une donnée codée en langage binaire (0 et 1). Nous allons voir ici deux types d'images.Image matricielle (de matrice) ou bitmap (BMP)
Ce type d'image très courant est divisé en petits carrés indivisibles, caractérisé par une couleur unique, appelé PIXEL (de PICture ELement).Sa résolution s'exprime en PPP, points par pouce (ou en DPI qui est la traduction anglaise).Image vectorielle (ex WMF)
Ce type d'image a pour caractéristique de décomposer l'image non en points, mais en segments, cercles, courbes, formes géométriques, fonctions de tracés pour la représenter.Nous allons voir dans ce paragraphe comment dans le cas d'une image matricielle l'ordinateur code un pixel.
Image en noir et blanc sans niveau de gris
Un seul BIT suffit par pixel , car le pixel est soit noir OU soit blanc et donc l'état est 1 OU 0 suffit pour le représenter.Image en niveau de gris
Ici, un pixel représente un point dont la "couleur" va du blanc au noir. Si le pixel est codé sur un octet, on dira que l'image est en 256 niveaux de gris puisque un octet peut représenter 256 valeurs.Image en 256 couleurs
Il s'agit de couleurs indexées et non de vraies TRUE COLOR, elles sont codées sur 8 bits ou 1 octet (de 0 à 255) donc 256 couleurs possibles. Ce codage est une table d'index appelée PALETTE qui établit une correspondance entre ces 256 valeurs et des couleurs systèmes WINDOWS codées elles sur 24 bits. Les valeurs de la palette sont modifiables, on peut créer, charger d'autres palettes.
Image en 65536 couleurs
Le pixel est codé par 2 octets de 8 bits, ici 2 octets codent pour une couleur. Cela nous permet d'avoir 2^16 = 65536 couleurs différentes.Image en 16 Millions de couleurs en RVB (RGB en anglais)
Le pixel est ici codé par 3 octet de 8 bits, chaque octet de 8 bits représente une des trois couleurs primaires (rouge, vert, bleu). Donc le pixel est codé sur 24 bits (8*3). Ce typede codage est aussi appelé mode TRUE COLOR.Donc si nous résumons nous avons:
- Un octet pour le ROUGE (de 0 signifiant qu'il n'y a pas de couleur à 255 signifiant l'intensité maximale de la couleur)
- Un octet pour le VERT (de 0 signifiant qu'il n'y a pas de couleur à 255 signifiant l'intensité maximale de la couleur)
- Un octet pour le BLEU (de 0 signifiant qu'il n'y a pas de couleur à 255 signifiant l'intensité maximale de la couleur)
Ce qui donne un total de 16 777 216 couleurs possibles !
Total = 256*256*266 = 16 777 216
Image en 32 bits
Le pixel est codé par 4 octets de 8 bits, ici 4 octets codent pour une couleur. Ici c'est comme si l'on part d'une image 24 bits et qu'on rajoute une composante qui peut être une couleur, une texture ou la transparence cela nous amène à une image en 32 bits vu que un pixel est codé sur 4 octets.Calcul théorique de la taille des images (exemple 640 x 480 pixels)
N/B:(640*480*1) / 8 = 34 400 octets
Taille relevée avec Paintbrush = 34 462 octets
256 couleurs:
(640*480*8)/8 = 307 200 octets
Taille de 308 278 relevée avec Paintbrush
65536 couleurs:
(640*480*16)/8 = 614 400 octets
16 M de couleurs:
(640*480*24) /8 = 921 600 octets
Taille relevée avec Paintbrush = 921 654 octets
32 bits:
(640*480*32)/8 = 1 228 800
Nous pouvons constater que la taille théorique des images ne correspond pas à la valeur donnée par Paintbrush. Nous pouvons croire que c'est une erreur de notre part, mais pas du tout, en fait les octets supplémentaires sont réservés à la description générale de l'image (nom du fichier, taille, résolution, codage BMP...) appelée en-tête (ou header) de ce fait ils augmentent la taille du fichier.
Les principaux paramètres utilisés pour la description d'un fichier image sont les suivants:
- Dimension de l'image (définie par le nombre de pixels par ligne et le nombre de lignes)
- Méthode de rangement des pixels
- Méthode de rangement des bits d'un pixel
- Algorithme de compression
- Nombre de bits par pixel
- Structure d'un pixel: codage de la couleur
4 - Introduction à la compression
Nous allons étudier plusieurs types de compression dans ce dossier. Mais tout d'abord nous allons introduire des notions fondamentales à la compréhension du principe de la compression.

La partie gauche donne la représentation visuelle de l'image. Dans cette représentation, un pixel est codé par un nombre entre 0 (blanc) et 255 (noir).
La partie droite montre que l'on peut représenter la même portion d'image en utilisant une convention: l'image est codée par des nombres qui indiquent le nombre d'occurrences d'une des 2 couleurs. Le nombre d'occurrence est obtenu en parcourant les pixels de haut en bas et de gauche à droite. Ainsi, l'image est formée de 5 pixels noirs suivi de un pixel blanc et terminée par 10 pixels noirs. La forme compressée comprend 3 nombres. Cet algorithme ne fonctionne qu'avec une image en noir et blanc. On appelle cela une compression RLE, on définira cette méthode dans la suite de notre dossier.
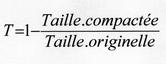
Schéma de la compression symétrique:
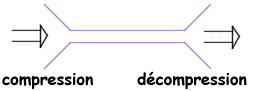
La compression asymétrique demande plus de travail pour l'une des deux opérations, on recherche souvent des algorithmes pour lesquels la compression est plus lente que la décompression. Les algorithmes plus rapides en compression qu'en décompression peuvent être nécessaires lorsque l'on archive des données auxquelles on accède peu souvent (pour des raisons de sécurité par exemple) et pour lesquelles on ne veut pas perdre de temps à archiver.
La compression d'une image numérique
La figure ci-dessous représente un extrait de 16 pixels d'une image en noir et blanc. Tous les pixels sont noirs à l'exception d'un seul.La partie gauche donne la représentation visuelle de l'image. Dans cette représentation, un pixel est codé par un nombre entre 0 (blanc) et 255 (noir).
La partie droite montre que l'on peut représenter la même portion d'image en utilisant une convention: l'image est codée par des nombres qui indiquent le nombre d'occurrences d'une des 2 couleurs. Le nombre d'occurrence est obtenu en parcourant les pixels de haut en bas et de gauche à droite. Ainsi, l'image est formée de 5 pixels noirs suivi de un pixel blanc et terminée par 10 pixels noirs. La forme compressée comprend 3 nombres. Cet algorithme ne fonctionne qu'avec une image en noir et blanc. On appelle cela une compression RLE, on définira cette méthode dans la suite de notre dossier.
Le taux de compression
Le taux de compression sert à évaluer la qualité de la compression en faisant l'opération suivante:
Compression et décompression
La compression et la décompression nécessitent 2 algorithmes. Le premier transforme les données de façon qu'elles occupent moins de place. Le second effectue la transformation inverse. Le résultat de ces deux transformations enchaînées doit produire le même résultat que les données de départ. C'est-à-dire qu'une compression suivie d'une décompression ne doit pas changer les données. Cependant, pour la compression d'images, il est acceptable de perdre un peu d'information pour obtenir un taux de compression plus élevé. L'image résultante n'est donc pas identique, bien que très proche visuellement. On dit alors que c'est une compression avec perte d'information.Compression symétrique et asymétrique
Dans le cas de la compression symétrique, la même méthode est utilisée pour compresser et décompresser l'information, il faut donc la même quantité de travail pour chacune de ces opérations. C'est ce type de compression qui est utilisé dans les transmission de données.Schéma de la compression symétrique:
La compression asymétrique demande plus de travail pour l'une des deux opérations, on recherche souvent des algorithmes pour lesquels la compression est plus lente que la décompression. Les algorithmes plus rapides en compression qu'en décompression peuvent être nécessaires lorsque l'on archive des données auxquelles on accède peu souvent (pour des raisons de sécurité par exemple) et pour lesquelles on ne veut pas perdre de temps à archiver.
Les types de compressions
Il existe deux grandes familles de compression, la compression sans perte et la compression avec perte, que nous allons tenter d'expliquer.5 - Sans perte: méthodes basées sur les répétitions
Le RLE consiste à reconnaître les répétitions et à réécrire le texte en les mettant en évidence. Prenons par exemple le texte suivant:
"ainsi font font font les petites marionnettes, ainsi font font font les petites marionnettes,"
Cette phrase contient 94 caractères (l'espace comptant comme un caractère).
Ainsi, en suivant cette méthode nous obtenons le texte suivant:
(ainsi (font)×3 les petites marionnettes, ) ×2
Cette écriture est dans un format compressé et indique que la partie du texte placée entre parenthèses doit être répétée autant de fois indiquée par le nombre qui suit.Donc, lors de la décompression nous obtenons:
Ainsi(font) ×3 sera remplacé par " font font font "
La phrase contient désormais 42 caractères. Nous avons donc compressé un texte contenant 94 caractères en un texte comprenant 42 caractères.
Exemple
Nous allons prendre ici une partie d'une image et afin que l'on puisse différencier les pixels on a agrandi cette image. Nous pouvons donc voir des carrés qui représentent les pixels. Attention, cet exemple n'est pas à l'échelle.

Nous avons un rectangle de 6 x 5 pixels qui sont définis chacun par 3 couleurs et 1 octet est défini par 8 bits. Nous allons "balayer" ce carré ligne par ligne. Cela nous donne:
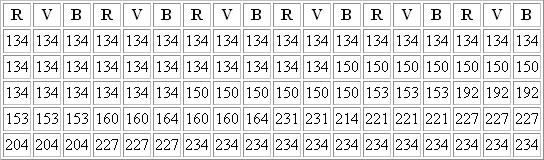
Nombre d'octets total 18 x 5 = 90 octets sans compression.
Nous avons donc:
28 x 134 + 6 x 150 + 6 x 134 + 6 x 150 + 3 x 153 + 3 x 192 + 3 x 153 + 2 x 160 + 1 x 164 + 2 x 231 + 2 x 214 + 3 x 221 + 3 x 227 + 3 x 204 + 3 x 227 + 12 x 234
Etablissons maintenant la correspondance entre ces valeurs entières et le binaire:
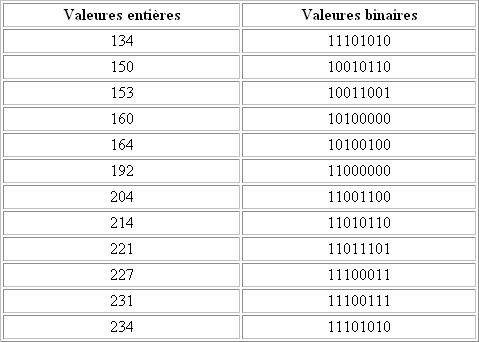
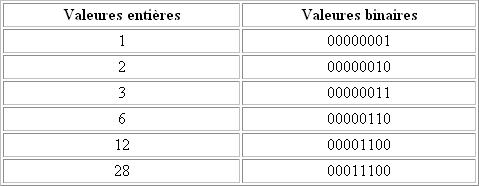
Etablissons aussi le multiple en binaire:
Tout cela nous amène au fichier compressé suivant:
00011100 11101010 00000110 10010110 00000110 11101010 00000110 10010110 00000011 10011001 00000011 11000000 00000011 10011001 00000010 10100000 00000001 10100100 00000010 11100111 00000010 11010110 00000011 11011101 00000011 11100011 00000011 11001100 00000011 11100011 00001100 11101010
Nous avons codé l'image sur 32 octets au lieu des 90 !! Nous ne comptons pas les octets de l'entête.
"ainsi font font font les petites marionnettes, ainsi font font font les petites marionnettes,"
Cette phrase contient 94 caractères (l'espace comptant comme un caractère).
Ainsi, en suivant cette méthode nous obtenons le texte suivant:
(ainsi (font)×3 les petites marionnettes, ) ×2
Cette écriture est dans un format compressé et indique que la partie du texte placée entre parenthèses doit être répétée autant de fois indiquée par le nombre qui suit.Donc, lors de la décompression nous obtenons:
Ainsi(font) ×3 sera remplacé par " font font font "
La phrase contient désormais 42 caractères. Nous avons donc compressé un texte contenant 94 caractères en un texte comprenant 42 caractères.
Exemple
Nous allons prendre ici une partie d'une image et afin que l'on puisse différencier les pixels on a agrandi cette image. Nous pouvons donc voir des carrés qui représentent les pixels. Attention, cet exemple n'est pas à l'échelle.
Nous avons un rectangle de 6 x 5 pixels qui sont définis chacun par 3 couleurs et 1 octet est défini par 8 bits. Nous allons "balayer" ce carré ligne par ligne. Cela nous donne:
Nombre d'octets total 18 x 5 = 90 octets sans compression.
Nous avons donc:
28 x 134 + 6 x 150 + 6 x 134 + 6 x 150 + 3 x 153 + 3 x 192 + 3 x 153 + 2 x 160 + 1 x 164 + 2 x 231 + 2 x 214 + 3 x 221 + 3 x 227 + 3 x 204 + 3 x 227 + 12 x 234
Etablissons maintenant la correspondance entre ces valeurs entières et le binaire:
Etablissons aussi le multiple en binaire:
Tout cela nous amène au fichier compressé suivant:
00011100 11101010 00000110 10010110 00000110 11101010 00000110 10010110 00000011 10011001 00000011 11000000 00000011 10011001 00000010 10100000 00000001 10100100 00000010 11100111 00000010 11010110 00000011 11011101 00000011 11100011 00000011 11001100 00000011 11100011 00001100 11101010
Nous avons codé l'image sur 32 octets au lieu des 90 !! Nous ne comptons pas les octets de l'entête.
6 - Sans perte: méthodes de type dictionnaire
La première méthode consiste à reconnaître les répétitions et à trouver un alphabet pour recoder l'information. Le format compressé est divisé en 2 parties: la première (avant ##) définit un alphabet de mots séparés par des # qu'on appellera le dictionnaire, la seconde donne l'ordre des mots employés en utilisant leur numéro d'ordre d'apparition dans le dictionnaire.
Reprenons l'exemple précédent, avec la phrase de 94 caractères. On sépare ici les mots par le caractère #, ce qui donne:
#ainsi #font #les petites marionnettes, ##1#2#2#2#3#1#2#2#2#3
La phrase comprend maintenant 60 caractères. Le caractère # ne doit pas faire partie de l'alphabet de départ.
La seconde méthode se nomme LZW, du nom de ses auteurs, Lempel, Ziw et Welch. Elle vise à déceler des suites de bits ou d'octets similaires, autrement dit à identifier des motifs qui se retrouvent dans la succession de valeurs décrivant l'image. Chaque fois qu'une telle suite est rencontrée, l'algorithme la range dans un dictionnaire et lui affecte un identificateur, qui vient la remplacer les données d'origine. Les valeurs isolées sont conservées telles quelles. Les données sont alors communiquées par le dictionnaire accompagnées de la succession de codes d'identification et valeurs isolées.
Etant donné que cette méthode est de type dictionnaire, la compression et la décompression se font instantanément, et n'a pas besoin d'opération intermédiaire, car l'algorithme se réfère directement au dictionnaire. Les algorithmes vont utiliser un dictionnaire. C'est une structure de données dans laquelle nous allons stocker des mots rencontrés dans le texte ainsi que leur code associé. Le principe de l'algorithme de compression est de chercher à former des motifs de plus en plus longs. Dès qu'un motif est trouvé, il est inséré dans le dictionnaire et un code lui est associé.
On doit simplement construire des tables renfermant des centaines de mots courants et utiliser les index de ces tables pour la compression. Ces index sont construits dynamiquement, en examinant les données et en construisant une table basée sur ce texte. Évidemment, moins il y a de répétitions de mots dans le texte, moins efficace sera la compression.
Même si les techniques Huffman et LZW sont habituellement utilisées pour compresser du texte, le même concept peut être appliqué à d'autres structures telles que les graphiques, le son ou les structures composites.
L'algorithme LZW est pénalisé par le fait qu'il faut conserver le dictionnaire entre la compression et la décompression (et il peut être relativement gros).
Reprenons l'exemple précédent, avec la phrase de 94 caractères. On sépare ici les mots par le caractère #, ce qui donne:
#ainsi #font #les petites marionnettes, ##1#2#2#2#3#1#2#2#2#3
La phrase comprend maintenant 60 caractères. Le caractère # ne doit pas faire partie de l'alphabet de départ.
La seconde méthode se nomme LZW, du nom de ses auteurs, Lempel, Ziw et Welch. Elle vise à déceler des suites de bits ou d'octets similaires, autrement dit à identifier des motifs qui se retrouvent dans la succession de valeurs décrivant l'image. Chaque fois qu'une telle suite est rencontrée, l'algorithme la range dans un dictionnaire et lui affecte un identificateur, qui vient la remplacer les données d'origine. Les valeurs isolées sont conservées telles quelles. Les données sont alors communiquées par le dictionnaire accompagnées de la succession de codes d'identification et valeurs isolées.
Etant donné que cette méthode est de type dictionnaire, la compression et la décompression se font instantanément, et n'a pas besoin d'opération intermédiaire, car l'algorithme se réfère directement au dictionnaire. Les algorithmes vont utiliser un dictionnaire. C'est une structure de données dans laquelle nous allons stocker des mots rencontrés dans le texte ainsi que leur code associé. Le principe de l'algorithme de compression est de chercher à former des motifs de plus en plus longs. Dès qu'un motif est trouvé, il est inséré dans le dictionnaire et un code lui est associé.
On doit simplement construire des tables renfermant des centaines de mots courants et utiliser les index de ces tables pour la compression. Ces index sont construits dynamiquement, en examinant les données et en construisant une table basée sur ce texte. Évidemment, moins il y a de répétitions de mots dans le texte, moins efficace sera la compression.
Même si les techniques Huffman et LZW sont habituellement utilisées pour compresser du texte, le même concept peut être appliqué à d'autres structures telles que les graphiques, le son ou les structures composites.
Explication de l'algorithme de compression
Après initialisation du dictionnaire, l'algorithme pourra lire et traiter les caractères les uns après les autres. Il construit un motif de plus en plus long. Si ce motif existe déjà dans le dictionnaire, il en construit un encore plus long.L'algorithme LZW est pénalisé par le fait qu'il faut conserver le dictionnaire entre la compression et la décompression (et il peut être relativement gros).
7 - Sans perte: méthodes statistiques
D.A. Huffman a inventé en 1952, un algorithme de compression capable, à partir d'une analyse statistique des données, d'associer à celles les plus souvent présentes les codes les plus courts. Inversement, les données les plus rares se verront attribuer les codes les plus longs.
Cet algorithme permet d'obtenir de bons résultats, mais il faut conserver entre la compression et la décompression, le dictionnaire des codes utilisés.
Cette image contient 30 pixels. Si l'on considère qu'ils sont codés sur 3 octets, la taille de ce texte est de 30 x 3= 90 octet soit 720 bits. La table ci-dessous indique les fréquences des valeurs du pixel de notre exemple. Nous pouvons remarquer que certaines valeurs définissant un pixel apparaissent plus fréquemment que d'autres.
L'algorithme va associer aux valeurs les plus fréquentes le code le plus compact possible.
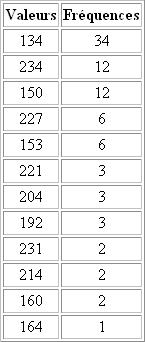
Pour réaliser cet algorithme, on commence avec une nouvelle table, similaire à la précédente, on place les valeurs dans une première colonne et leur fréquence dans la seconde. Les données sont triées par ordre de fréquence décroissante.
On construit ensuite le tableau, colonne par colonne, de gauche à droite. On effectue d'abord la somme des 2 fréquences les plus faibles. On reporte dans la colonne suivante toutes les fréquences en supprimant les deux plus faibles. Et en les remplaçant par leur somme. Ce nombre doit être positionné dans la colonne de sorte à respecter l'ordre décroissant. Chaque paire de l'ancienne colonne est annotée avec 0 pour la valeur la plus élevée et 1 pour la plus faible. On procède ainsi jusqu'à ce qu'il ait plus qu'un élément dans la colonne.
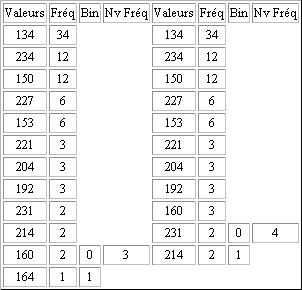
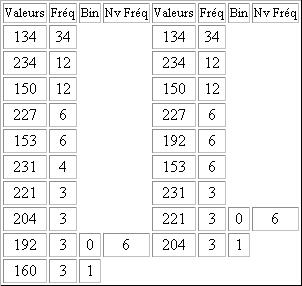
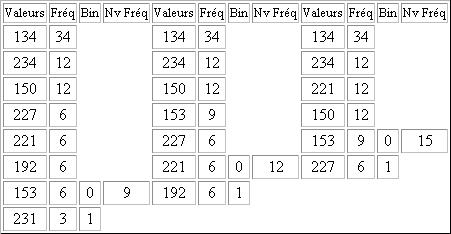
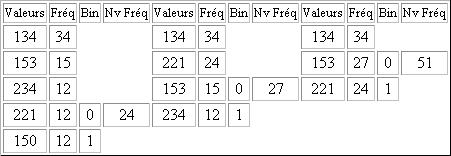
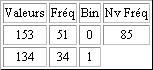
Légende:
Fréq = Fréquence
Nv Fréq = Nouvelle Fréquence
Bin = Binaire
Cette première étape permet de constituer un arbre. L'arbre est constitué de nœuds et de feuilles. Tous les nœuds ont deux liens vers d'autres nœuds ou des feuilles. On dit qu'il est le père de deux fils. Le lien de gauche est étiqueté 0 et celui de droite 1. Ce type d'arbre s'appelle un arbre binaire car tous les nœuds ont deux fils. Le nœud le plus élevé s'appelle la racine. On trouve alors le code d'une lettre en partant de sa position dans l'arbre, en remontant vers la racine tout en notant de droite à gauche les 1 et 0 rencontrés. Cet algorithme revient donc à construire un arbre binaire. On note sur chaque nœud les sommes des fréquences des fils. Les feuilles représentent les valeurs avec leurs fréquences. La racine indique donc la somme des valeurs du texte. Chaque branche correspond soit à 0, soit à 1. Pour compresser l'image, il suffit pour chaque valeurs de parcourir l'arbre en partant de la feuille correspondant à la valeur voulue, et de remonter jusqu'à la racine. Une fois arrivé, on émet les bits 1 ou 0 correspondant au chemin parcouru.
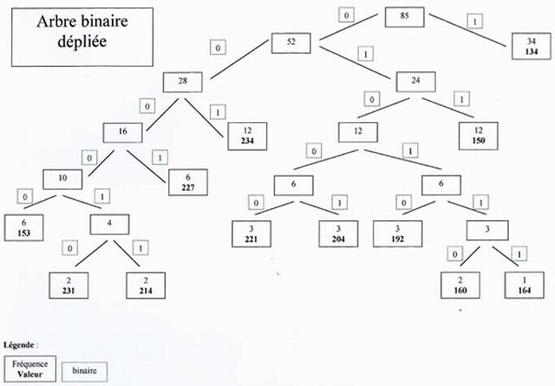
Dans un fichier, les bits sont représentés par groupe de huit et forment des octets. Le résultat de la compression de notre exemple est donc le suivant:
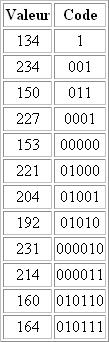
Cet algorithme permet d'obtenir de bons résultats, mais il faut conserver entre la compression et la décompression, le dictionnaire des codes utilisés.
La méthode
Reprenons l'exemple précédent:Cette image contient 30 pixels. Si l'on considère qu'ils sont codés sur 3 octets, la taille de ce texte est de 30 x 3= 90 octet soit 720 bits. La table ci-dessous indique les fréquences des valeurs du pixel de notre exemple. Nous pouvons remarquer que certaines valeurs définissant un pixel apparaissent plus fréquemment que d'autres.
L'algorithme va associer aux valeurs les plus fréquentes le code le plus compact possible.
Pour réaliser cet algorithme, on commence avec une nouvelle table, similaire à la précédente, on place les valeurs dans une première colonne et leur fréquence dans la seconde. Les données sont triées par ordre de fréquence décroissante.
On construit ensuite le tableau, colonne par colonne, de gauche à droite. On effectue d'abord la somme des 2 fréquences les plus faibles. On reporte dans la colonne suivante toutes les fréquences en supprimant les deux plus faibles. Et en les remplaçant par leur somme. Ce nombre doit être positionné dans la colonne de sorte à respecter l'ordre décroissant. Chaque paire de l'ancienne colonne est annotée avec 0 pour la valeur la plus élevée et 1 pour la plus faible. On procède ainsi jusqu'à ce qu'il ait plus qu'un élément dans la colonne.
Légende:
Fréq = Fréquence
Nv Fréq = Nouvelle Fréquence
Bin = Binaire
Cette première étape permet de constituer un arbre. L'arbre est constitué de nœuds et de feuilles. Tous les nœuds ont deux liens vers d'autres nœuds ou des feuilles. On dit qu'il est le père de deux fils. Le lien de gauche est étiqueté 0 et celui de droite 1. Ce type d'arbre s'appelle un arbre binaire car tous les nœuds ont deux fils. Le nœud le plus élevé s'appelle la racine. On trouve alors le code d'une lettre en partant de sa position dans l'arbre, en remontant vers la racine tout en notant de droite à gauche les 1 et 0 rencontrés. Cet algorithme revient donc à construire un arbre binaire. On note sur chaque nœud les sommes des fréquences des fils. Les feuilles représentent les valeurs avec leurs fréquences. La racine indique donc la somme des valeurs du texte. Chaque branche correspond soit à 0, soit à 1. Pour compresser l'image, il suffit pour chaque valeurs de parcourir l'arbre en partant de la feuille correspondant à la valeur voulue, et de remonter jusqu'à la racine. Une fois arrivé, on émet les bits 1 ou 0 correspondant au chemin parcouru.
Dans un fichier, les bits sont représentés par groupe de huit et forment des octets. Le résultat de la compression de notre exemple est donc le suivant:
8 - Avec perte: la compression JPEG
Historique
L'histoire commence à la fin des années 80, lorsque deux importants groupes de normalisation, le CCITT (Consultative Committe for International Telegraph and Telephone ) et l'ISO (Organisation Internationale de Standardisation) décidèrent de créer, appuyés par divers groupes industriels et universitaires, une norme internationale pour la compression d'images fixes. La mise en place d'un standard international était devenue nécessaire pour archiver ou pour faciliter l'échange des images dans des domaines aussi variés que les photos satellites, l'imagerie médicale, la télécopie couleur, ou la cartographie. C'est ainsi que fut créé le groupe JPEG (Joint Photgraphic Experts Group) à l'origine de la norme qui porte son nom. Cette norme comprend des spécifications pour les codages conservateurs (l'image est restituée identique à elle-même à la suite du codage) et non conservateurs (l'image est légèrement modifiée pendant le cycle de compression mais cette modification reste imperceptible pour l'œil) de l'image. Le JPEG est aujourd'hui largement utilisé dans les secteurs de l'informatique et de la communication (appareils photo numériques, scanners, imprimantes, télécopieurs...).Le principe général
Le principe de l'algorithme JPEG pour une image à niveaux de gris (étant donné qu'une image couleur est la somme de 3 images de ce même type, dans la suite du TIPE nous ne considérerons plus que ce genre d'images) est le suivant. La matrice des pixels de l'image numérique est décomposée en blocs de 8x8 pixels qui vont tous subir le même traitement. Une transformation linéaire, le plus souvent du type FFT (Fast Fourier Transform) ou DCT (Discret consine Transform) est réalisée sur chaque bloc. Ces transformations complexes concentrent l'information sur l'image en haut et à gauche de la matrice. Les coefficients de la transformée sont ensuite quantifiés à l'aide d'une table de 64 éléments définissant les pas de quantification. Cette table permet de choisir un pas de quantification important pour certaines composantes jugées peu significatives visuellement. On introduit ainsi un critère perceptif qui peut être rendu dépendant des caractéristiques de l'image et de l'application (taille du document). Des codages (prédictif, entropique, l'algorithme de Huffmann ou arithmétique), sans distorsion, sont ensuite réalisés en utilisant les propriétés statistiques des images. Ces compressions seront suivis d'une transformation inverse de la transformation initiale, conduisant à la restitution de l'image.Approfondissons un peu...
Soit un bloc de 8 x 8 pixels à 256 niveaux de gris.Remarque: Si l'on avait pris une image 24 bits on aurait eut trois matrices différentes; l'une codant pour le rouge, l'une codant pour le vert et l'une codant pour le bleu. On peut aussi ajouter une matrice pour la chrominance ou pour la luminance. Mais alors l'image sera codée sur 32 bits...
Matrice de pixels d'entrée:

La DCT
L'image est découpée en bloc de 8 x 8 pixel. Ensuite la Transformée en Cosinus Discète (DCT) est appliqué sur les pixels de chaque bloc. Cette transformation numérique est une variété de la transformée de Fourier. Elle permet de décrire chaque bloc en un graphique de fréquences (correspondant à l'importance et à la rapidité d'un changement de couleur) et en amplitudes (qui est l'écart associé à chaque changement de couleur) plutôt qu'en pixels et qu'en couleurs comme c'est le cas normalement. La DCT étant un procédé très complexe nous ne pouvons aller plus loin dans notre développement et une longue formule que l'on ne comprend pas n'apporterait rien... A ce niveau-ci il n'y a pas encore de pertes de données.Matrice DCT:
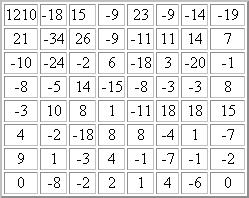
Les valeurs de la matrice DCT ont été arrondies à l'entier le plus proche. Le coefficient continu 1210 sur la composante (0,0) représente "la moyenne" de la grandeur d'ensemble de la matrice d'entrée. Cette moyenne n'est pas une moyenne statique mais un nombre proportionnel à la somme de toutes les valeurs du signal. Les autres valeurs de la DCT sont les "écarts" par rapport à cette moyenne. Lorsque l'on monte dans les hautes fréquences, les valeurs de la matrice ont tendance à s'approcher de 0 quand on s'eloigne du coin supérieur gauche de la matrice.
L'étape de la quantification de chaque bloc regroupe les ensembles de valeurs proches.
Ensuite, chaque amplitude originale sera remplacée par la valeur moyenne de l'intervale, c'est à dire l'étape de quantification est de diminuer la précision du stockage des entiers de la matrice DCT pour diminuer le nombre de bits occupés par chaque entier. C'est la partie non conservative de la méthode. Les basses fréquences sont conservées, la précision des hautes fréquences sont diminuées. La perte de précision est plus grande lorsqu'on s'éloigne de la position(0,0). Les valeurs de la matrice DCT sera divisée par la matrice de quantification.
La quantification
Supposons qu'une variable puisse prendre les valeurs 1, 2, 3, 4, 5... Si l'on prend un pas de quantification de 4 on garde le quotient de la division euclidienne de la valeur par le pas de quantification. Pour cela on utilise d'abord les congruences pour trouver le reste de la division euclidienne, cette division est de la forme a = bq + r avec 0 < r < b donc q = (a-r)/b. Donc pour trouver le reste il faut d'abord le calculer avec une congruences de la forme a congru à r modulo b.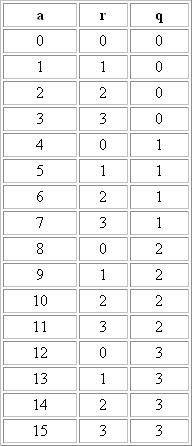
Donc si on prend un pas de quantification de 4 on va remplacer:
0, 1, 2, 3 par 0
4, 5, 6, 7 par 1
8, 9, 10, 11 par 2
12, 13, 14, 15 par 3
C'est à cette étape que nous allons perdre de l'information et nous allons la perdre d'une manière "astucieuse" parce que le pas de quantification dont dépend la précision de l'image restituée va dépendre de la position de la valeur dans la matrice. Nous allons prendre un pas relativement petit pour les valeurs importantes (en haut à gauche) et prendre un pas de plus en plus grand au fur et à mesure qu'on descend vers le bas et la droite de la matrice. l'ensemble des pas qui vont être utilisés constituent ce que l'on appelle une matrice de quantification. Une matrice peut être fabriquée grâce une petite formule:
Q( i , j ) = 1 + ( 1 + i + j ) x Fq, Fq est le facteur de qualité
Si l'on prend ici un facteur de qualité de 5 nous obtenons après calcul la matrice suivante. Le calcul est très simple, on prend la position de chaque pixel dans la matrice DCT, la valeur du pixel n'intervient pas dans le calcul, puis on met le résultat dans la matrice de quantification aux même coordonnées que dans la matrice DCT. Simple non ?
Matrice de quantification:

Matrice DCT quantifiée
Pour cela on divise juste comme expliqué ci-dessus la matrice DCT par la matrice de quantification. Et cela nous donne: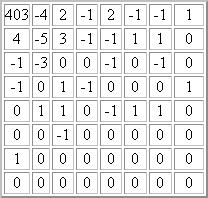
Lors de la décompression, il suffira de multiplier la valeur de la matrice DCT quantifiée par l'élément correspondant de la matrice de quantification pour obtenir une approximation de la DCT. La matrice obtenue est appelée matrice DCT déquantifiée.
L'encodage
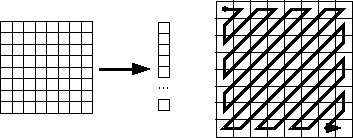
Le codage de la matrice DCT quantifiée se fait en parcourant les éléments dans l'ordre imposé par une séquence appelée Séquence zigzag. Les éléments sont parcourus en commençant par les basses fréquences puis ensuite en traitant les fréquences de plus en plus élevées. Etant donné qu'il y a beaucoup de composantes de hautes fréquences qui sont nulles dans la matrice DCT, la séquence zigzag engendre de longues suites de 0 consécutifs. D'une part, les suites de valeurs nulles sont simplement codées en donnant le nombre de 0 successifs. D'autre part, les valeurs non nulles seront codées en utilisant une méthode statitisque de type Huffman.Remarque: Les fréquences les plus hautes se situent en bas à droite et les fréquences les plus basses se situent en haut à gauche.
9 - Avec perte: la compression fractale
Les courbes
Introduction par un exemple simple: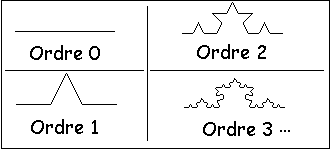
- Soit le niveau 0 de la courbe, constitué d'un segment de droite.
- On dessine un triangle équilatéral dont le côté à une longueur égale au tiers du segment initial.De plus ce triangle pointe vers le haut.
- On applique ce même procédé à chacun des segments de droite ainsi constitués (remarquons que la transformation est appliquable à l'infini).
Les images
Une image fractale est caractérisée par le type de transformation qu'elle a subit, l'algoritme consiste principalement a coder celle-ci comme une suite de transformations. En effet, les données d'une image contiennent généralement un ensemble plus ou moins grand d'éléments redondants (partie similaire sur l'image ou auto-similarités). Etant inutile de stocker ces éléments autant de fois qu'ils sont présents, la taille de l'image décroît. Pour obtenir une compression intéressante, on influe sur l'image avec la façon dont travaille la vision humaine. En effet, notre oeil est insensible à certaines pertes d'informations (le cerveau assurant, par comparaison, la correction de l'erreur générée). Ainsi, on peut modifier l'image, raisonnablement, de manière à augmenter le nombre de suites redondantes. Tout ça en faisant en sorte que l'image transformée converge vers l'image initiale, qui est alors l'attracteur de la transformation. Une même transformation peut donc être appliquée à des images différentes, l'attracteur étant, quand à lui différent.Exemple de types de transformation:
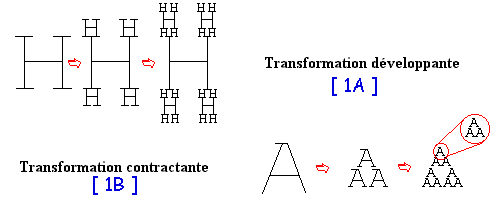
La compression fractale
La compression d'une image fractale consiste à mettre en relation un modèle mathématique avec celle-ci afin de lui appliquer un transformation contractante. Il faudra ensuite définir les auto-similarités, afin de ne les sauvegarder qu'une seule fois. Cette recherche correspond à une transformation afine qui se résume à une aproximation de l'image d'origine, incluant donc un taux d'erreur de l'image finale variant selon la complexité de la transformation; c'est ce qui donne le taux de compression. Prenons le cas de l'exemple 1B, l'attracteur (image d'origine, qui est la lettre A ) de cette transformation subit la variation d'échelle. Le produit de ces transformations multiples offre une caractéristique intéressante, car les détails supplémentaires apportés à l'image transformée sont générés "automatiquement" par la méthode employée, détails qui dans certains cas sont très réalistes pour de faibles agrandissements. Cette méthode, implique un taux d'erreur +/- variable à la représentation finale de l'image d'origine, ce qui est normal puisqu'il s'agit d'une approximation mathématique.Imaginons une photocopieuse dont le but est de recopier l'entrée trois fois en divisant par deux son échelle comme illustré sur a figure ci-dessous:

A chaque cycle de la copie, le document qui vient de sortir est remis en entrée de la photocopieuse de ce fait, après de nombreuses copies comportant les mêmes transformations (ici division par 2 de l'échelle puis recopie de la source 3 fois), la sortie convergera vers ce que l'on appelle un attracteur, c'est à dire une image qui lorqu'on la remet en entrée de cette photocopieuse donne en sortie la même image. La transformation utilisée en exemple est l'une des très nombreuses transformations possibles. Et on peut immédiatement comprendre que d'autres transformations conduiraient à d'autres attracteurs.
Indépendance de l'attracteur vis-à-vis de l'image d'origine:
Mais considérons maintenant deux images totalement différentes, et appliquons à chacune d'elles simultanément les mêmes transformations. Comme le montre la figure ci-dessous, les deux images (a et b) qui au départ étaient dissemblables donnent lieu au même attracteur (c).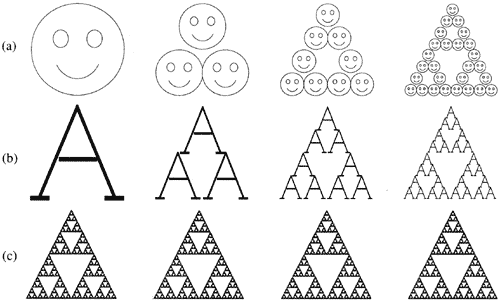
En fait, plus on réalise de copies, plus l'image d'origine disparait pour ne devenir qu'un point. Mais ce point existe en plusieurs copies agencées d'une certaine manière que définit la transformation utilisée. Ainsi, un attracteur ne dépend que de la transformation utilisée. En pratique, ces transformations sont des applications affines, c'est à dire des transformations du plan dans le plan telles que chacune de ces transformations effectue au moins une des opérations suivantes:
- Etirement
- Rotation
- Translation
En pratique, l'ensemble de ces transformations est suffisant pour pouvoir donner lieu à un ensemble riche d'attracteurs.
La compression fractale consiste non pas à enregistrer les informations propres de l'image, mais plutôt les transformations nécessaires à la constitution de l'image en tant qu'attracteur. Connaissant cette suite de transformations, l'image pourra être reconstituée en partant de n'importe quelle image source (par exemple une image entièrement noire) car celle-ci devenant un point parmi d'autres.
Voyons à présent la taille nécessaire au codage d'une transformation (on verra plus tard que cela n'est pas suffisant pour coder une image quelconque complètement).
Comme il a été vu précédemment, chaque transformation est définie à partir de 6 réels qui sont codables sur 32 bits. Il suffit donc de 192 bits pour stocker une transformation.
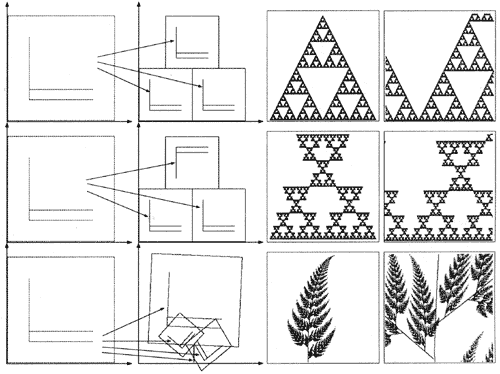
Pour compresser l'image de la fougère ci-dessous (figure 4), comme il ne faut que 4 transformations (on ne prend pas encore en compte les transformations liées aux niveaux de gris), il suffira de 4 x 192 bits = 768 bits (96 octets) pour stocker l'image alors qu'il faut environ 12kbits pour stocker l'image avec la résolution actuelle.
Processus de compression
L'idée de base de ce procédé de compression d'images est de trouver l'attracteur de l'image à compresser, au sens mathématique du terme si l'on modélise une image comme une application de {1,...,N}*{1,...,N} vers {0,...2p-1} ou N est le côté de cette image en nombre de pixels et p est le nombre de bits que l'on utilise pour coder cette image (pour p bits, on obtient un nombre de couleurs différentes utilisables de 2 exposant p).C'est parce qu'une manière de définir une fractale en mathématiques est de décrire une fractale comme l'unique point fixe d'un attracteur. Nous allons donc tenter d'expliquer comment fonctionne ce type de compression, mais dans les grandes lignes.
Tout comme pour la compression Jpeg, l'algorithme découpe l'image en blocs-parents carrés de 16 pixels de côtés, eux-mêmes subdivisés en 4 blocs-fils carrés de 8 pixels de côté. Le travail principal de l'algorithme de compression est de calculer, pour chacun de ces blocs-parent et de ces blocs-fils, l'attracteur qui lui est associé. On ne trouve généralement jamais exactement l'attracteur exact associé à un bloc mais le travail consiste à en trouver un le plus fidèle possible. Chaque attracteur spécifique à un seul bloc décrit ce bloc de la manière suivante.
Considérons un bloc et son attracteur associé: si, par la suite, l'on prend n'importe quel autre bloc de la même taille mais dont le rendu n'a rien a voir avec ce dernier, et que l'on fait l'image de ce bloc par l'attracteur considéré, on se rapproche chaque fois plus du premier bloc. C'est la propriété de contractance de l'attracteur, via un théorème appelé théorème du "collage" qui garantisent cette convergence.
De cette manière, il semble exister une bijection entre tout bloc et son attracteur associé. Et comme l'espace physique que prend l'attracteur, par rapport à celui que prend le bloc, est bien inférieure le gain en espace physique de l'image qui n'est rien d'autre qu'un assemblage disjoint de ces blocs s'en trouve diminué; c'est le passage de la description d'un bloc par son attracteur qui constitue l'étape de compression de ce processus. En effet, cet attracteur peut-être décrit approximativement par deux paires de fonctions, une de réajustement, l'autre d'intensité qui sont codées sur peu d'espace physique.
Il s'agit d'une approximation car si l'on désirait calculer précisément l'attracteur de chaque bloc, il faudrait bien plus que deux paires de fonctions pour le décrire, mais plutôt 2n fonctions telles que n serait d'autant plus grand que la précision requise serait importante. Dans la pratique, il est possible de décrire chaque bloc assez précisément à l'aide d'un attracteur simple constitué de deux paires de fonctions. Pour déterminer les fonctions qui décrivent cet attracteur, on doit utiliser la méthode des moindres carrés qui, utilisée intensivement, est coûteuse en temps de calcul, ce qui ralentit le processus de compression.
Ce procédé de compression d'images est non conservatif puisque cette correspondance évoquée précédemment ne sera pas parfaite. Cela va donc introduire des infidélités entre l'image originale et l'information que détient l'image compressée.
Le fichier compressé contient donc les informations sur les attracteurs des blocs-parents (à savoir: la paire de fonctions d'intensité, la paire de fonctions de réajustement étant fixée et stockée au début de l'en-tête), puis celles concernant les différents blocs. D'autres informations telles celles qui concernent la taille de l'image sont contenues dans l'en-tête.
Les avantages:
- La compression fractale permet un puissant zoom fractal pour agrandir une image sans effet de pixellisation.
- Son taux de compression est très avantageux, tout en conservant un aperçu fidèle.
- Un effet de lissage flou disponible en traitement d'images.
Les inconvénients:
- Ce type de compression n'a pas encore fait l'objet de l'édition d'une norme.
- La compression reste lente malgré toutes les améliorations.
- La compression produit un flou dans l'image.
10 - Avec perte: la compression par ondelettes
Cette partie étant très particulièrement pointue nous ne pouvons pas faire une explication très avancée mais seulement énoncer ce type de compression dans les grandes lignes.
Principe de fonctionnement à l'aide d'un exemple
De même que le "JPEG", la compression d'images par ondelettes est une méthode "destructrice", c'est à dire que lors de la compression, des informations sont définitivement perdues par rapport à l'image originale.
Le schéma de fonctionnement est à peu près le même:
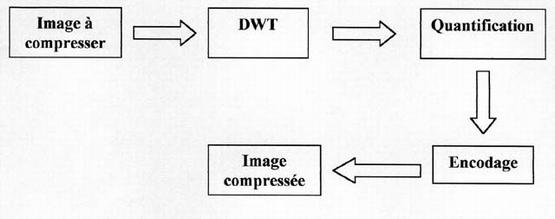
L'image est un ensemble de pixels qui sont repésentés dans une matrice par un entier. Cette matrice subit ensuite une DWT (Discret Wavelet Transform), c'est la tranformation en ondelettes. Puis grâce à la phase de quantification, les valeurs des images de détails inférieures à un certain niveau sont éliminées en fonction de l'efficacité recherchée, c'est à ce niveau qu'on perd de l'information. Enfin la matrice quantifiée subit un encodage.
La transformation en ondelettes ou en sous bande.
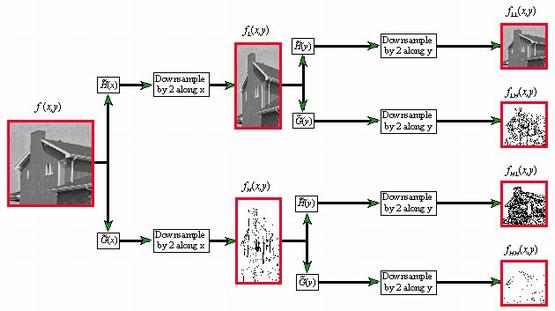
La transformation par ondelettes est une technique de traitement de signal qui consiste à décomposer une image en une miriade de sous-bandes, c'est à dire des images de résolution inférieure.
Pour obtenir un niveau inférieur de sous bande, on moyenne les pixels de l'image originale deux à deux suivant l'axe horizontal (par exemple: H(X) = (Xn + Xn+1) / 2 ). Puis on calcule l'erreur entre l'image originale et l'image sous-échantillonnée dans le sens horizontal (par exemple: G(X) = (Xn - Xn+1) / 2 ). Pour chacune des deux images intermédiaires, on moyenne les pixels deux à deux suivant l'axe vertical (par exemple: H(Y) = (Yn + Yn+1) / 2 ). Enfin pour chacune des deux images intermédiaires, calculer l'erreur suivant l'axe vertical (par exemple: G(Y) = (Yn - Yn+1) / 2 ).
Le résultat est une image d'approximation qui a une résolution divisée par 2 et trois images de détails qui donnent les erreurs entre l'image originale et l'image d'approximation. Cette transformation est répétée autant de fois que nécessaire pour obtenir le nombre voulu de sous-bandes.

Les blocs JPEG 8 x 8 sont quantifiés indépendamment les uns des autres ce qui ne permet pas de réduire les redondances au delà d'un bloc. Au contraire, la compression par ondelettes est une méthode globale sur toute l'image. Cet avantage se traduit par une efficacité encore plus importante sur les grosses images. Une image de 50 Mo peut être réduite à 1 Mo.
Le ratio de compression est directement programmable dans la compression par ondelettes en format JPEG 2000. Il est donc possible de prévoir la taille du fichier compressé, quelle que soit l'image, ce qui n'est pas faisable avec la méthode DCT du JPEG.
La compression par ondelettes est intrinsèquement progressive ce qui permet de reconstruire facilement l'image à plusieurs résolutions.
Historique
La théorie sur laquelle repose la technologie des ondelettes est récente: début des années 1980. Bien que plusieurs scientifiques aient contribué à ce projet, le géophysicien français Jean Morlet est généralement reconnu comme étant le père de cette méthode de compression.Principe de fonctionnement à l'aide d'un exemple
De même que le "JPEG", la compression d'images par ondelettes est une méthode "destructrice", c'est à dire que lors de la compression, des informations sont définitivement perdues par rapport à l'image originale.
Le schéma de fonctionnement est à peu près le même:
L'image est un ensemble de pixels qui sont repésentés dans une matrice par un entier. Cette matrice subit ensuite une DWT (Discret Wavelet Transform), c'est la tranformation en ondelettes. Puis grâce à la phase de quantification, les valeurs des images de détails inférieures à un certain niveau sont éliminées en fonction de l'efficacité recherchée, c'est à ce niveau qu'on perd de l'information. Enfin la matrice quantifiée subit un encodage.
La transformation en ondelettes ou en sous bande.
La transformation par ondelettes est une technique de traitement de signal qui consiste à décomposer une image en une miriade de sous-bandes, c'est à dire des images de résolution inférieure.
Pour obtenir un niveau inférieur de sous bande, on moyenne les pixels de l'image originale deux à deux suivant l'axe horizontal (par exemple: H(X) = (Xn + Xn+1) / 2 ). Puis on calcule l'erreur entre l'image originale et l'image sous-échantillonnée dans le sens horizontal (par exemple: G(X) = (Xn - Xn+1) / 2 ). Pour chacune des deux images intermédiaires, on moyenne les pixels deux à deux suivant l'axe vertical (par exemple: H(Y) = (Yn + Yn+1) / 2 ). Enfin pour chacune des deux images intermédiaires, calculer l'erreur suivant l'axe vertical (par exemple: G(Y) = (Yn - Yn+1) / 2 ).
Le résultat est une image d'approximation qui a une résolution divisée par 2 et trois images de détails qui donnent les erreurs entre l'image originale et l'image d'approximation. Cette transformation est répétée autant de fois que nécessaire pour obtenir le nombre voulu de sous-bandes.
Avantages des ondelettes (JPEG 2000) par rapport à la DCT (JPEG)
La compression DCT du format JPEG analyse l'image par bloc de 8 par 8 pixels ce qui produit un effet de mosaïque (les limites des blocs sont visibles à fort taux de compression). La compression par ondelettes ne présente pas cet effet de mosaïque indésirable. Il est donc possible de compresser des images par ondelettes avec un taux de compression élévé tout en conservant une bonne qualité picturale.Les blocs JPEG 8 x 8 sont quantifiés indépendamment les uns des autres ce qui ne permet pas de réduire les redondances au delà d'un bloc. Au contraire, la compression par ondelettes est une méthode globale sur toute l'image. Cet avantage se traduit par une efficacité encore plus importante sur les grosses images. Une image de 50 Mo peut être réduite à 1 Mo.
Le ratio de compression est directement programmable dans la compression par ondelettes en format JPEG 2000. Il est donc possible de prévoir la taille du fichier compressé, quelle que soit l'image, ce qui n'est pas faisable avec la méthode DCT du JPEG.
La compression par ondelettes est intrinsèquement progressive ce qui permet de reconstruire facilement l'image à plusieurs résolutions.
11 - Conclusion
La compression des données est appelée à prendre un rôle encore plus important en raison du développement des réseaux et du multimédia. Son importance est surtout due au décalage qui existe entre les possiblités matérielles des dispositifs que nous utilisons (débits sur Internet, sur Numéris et sur les divers cables, capacité des mémoires de masse,...) et les besoins qu'expriment les utilisateurs (visiophonie, vidéo plein écran, transfert de quantités d'informations toujours plus importantes dans des délais toujours plus brefs). Les méthodes déjà utilisées couramment sont efficaces et sophistiquées (Huffman, LZW, JPEG) et utilisent des théories assez complexes, les méthodes émergentes sont prometteuses (fractales, ondelettes) mais nous sommes loin d'avoir épuisé toutes les pistes de recherche. Les méthodes du futur sauront sans doute s'adapter à la nature des données à compresser et utiliseront l'intelligence artificielle.
Compress. images
1 - Introduction2 - Le codage binaire, hexa, ascii et les images numériques3 - Canon à électrons, images et couleurs4 - Introduction à la compression5 - Sans perte: méthodes basées sur les répétitions6 - Sans perte: méthodes de type dictionnaire7 - Sans perte: méthodes statistiques8 - Avec perte: la compression JPEG9 - Avec perte: la compression fractale10 - Avec perte: la compression par ondelettes11 - Conclusion
Populaires