Ce dossier nous présente la plate-forme BOINC, il explique son principe de fonctionnement sans oublier de détailler les principaux projets scientifiques qui en bénéficient. Il nous est proposé par Gus et Pas, tout deux membres actifs du projet BOINC. Vous pouvez les retrouver sur notre forum.
En complément, un didacticiel explicitant l'installation et la configuration du client BOINC est disponible sur Techno-Science.net sous la forme d'un autre dossier, BOINC: didacticiel installation et configuration.
Introduction
BOINC (Berkeley Opening Infrastructure for Network Computing) est une plate-forme de calcul distribué open source créée par l'université de Berkeley. Son objectif est de fournir, par l'intermédiaire des ordinateurs d'internautes volontaires, une gigantesque puissance de calcul dans un but de recherche scientifique. Elle regroupe aujourd'hui plusieurs centaines de milliers d'utilisateurs et couvre ainsi une puissance de calcul de plus de 400 teraflops (soit 400 000 milliards d'opérations en virgule flottante à la seconde !).
2 - Le calcul distribué dans le cadre du projet BOINC
On sait tous que les calculs à effectuer pour un problème scientifique de grande envergure sont énormes et nécessitent une puissance importante. Pour effectuer ces calculs il existe deux solutions:
- le supercalculateur, qui coûte cher et qui nécessite beaucoup de maintenance
- le calcul distribué, qui utilise une multitude de machines réparties sur un réseau (pourquoi pas Internet). Cette architecture est peu couteuse et possède une puissance de calcul pouvant être supérieure à un supercalculateur.
Le calcul distribué est de plus en plus préféré au supercalculateur. BOINC fonctionne sur ce type d'architecture.
Les centres de recherche qui veulent utiliser BOINC, en tant que ressource de calcul, constituent un projet en mettant un serveur à disposition. Chaque utilisateur peut s'attacher au/x projet/s qui l'intéresse/nt.
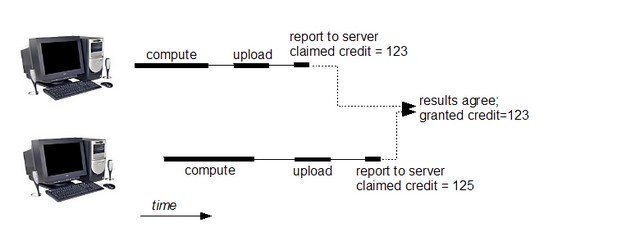
Le calcul distribué consiste à diviser un gros calcul en plusieurs petites unités appelées unités de travail (Work Units - WU). Ces unités sont alors envoyées sur le client BOINC d'un utilisateur. Celui-ci calcule cette unité sur son ordinateur personnel en se servant des ressources inutilisées de son processeur, ce qui ne gêne pas ou très peu les applications lancées en parallèle (multitâches) sur l'ordinateur.
Une fois l'unité calculée, le client BOINC utilise Internet pour la transférer au serveur ; les unités de travail sont de petites tailles et ne nécessitent pas de connexion à haut débit.
Un système de crédits fictifs
A chaque unité renvoyée au serveur, le compte de l'utilisateur est incrémenté d'un nombre de crédits, les cobblestones, qui servent uniquement à effectuer un classement des utilisateurs.
L'Alliance francophone
Le système de crédit décrit ci-dessus permet d'effectuer un classement des utilisateurs mais également des équipes. L'alliance francophone est l'une des meilleures équipes mondiales et a pour but de regrouper tous les francophones. Au sein de l'alliance il est possible de rejoindre ou de créer une "miniteam", géographique ou non; par exemple l'Equipe de la Science ou la communauté Techno-Science.net.
Très important: BOINC n'a aucun but lucratif.
Les différents projets
Il existe plusieurs projets scientifiques dans plusieurs domaines; la médecine, la biologie, la météorologie, l'astronomie, la physique, les mathématiques. Les pages qui suivent présentent une sélection de projets.
3 - Les projets Seti@home et Einstein@home
Le projet Seti@home
SETI est l'abréviation de Search for the ExtraTerrestrial Intelligence (recherche d'une "intelligence" extraterrestre). Ce projet de l'université de Berkeley en Californie est né en 1984.
Seti@home est sans doute le premier projet de calcul distribué à avoir été largement diffusé avec environ 5 000 000 d'inscrits dans sa première version. Il utilise le télescope d'Arecibo, le plus grand radiotélescope du monde.
Les données collectées en scrutant le ciel, sont analysées par les clients SETI, à la recherche de signaux ayant une structure qui pourrait avoir été générée par une forme d'intelligence (en distinction du bruit aléatoire).
Le radiotélescope d'Arecibo.
SETI@Home effectue une série de FFT (extraction de la composante fréquentielle d'un signal) sur les données qu'on lui donne à analyser. Si le signal est de nature aléatoire, on n'observera pas de "pic" sur un canal donné. Si un pic est observé, cela devient intéressant: c'est peut être une émission extraterrestre.
Pour en être sûr SETI@Home vérifie si le spectre est légèrement étalé sur d'autres fréquences (ceci est dû à la rotation de la Terre). De plus, le télescope d'Arecibo étant fixe, de par la rotation de la Terre, le signal va être capté d'un côté de l'antenne, passera par son centre puis s'éloignera vers l'autre coté pour ne plus être capté. Le pic d'un éventuel signal extraterrestre verra donc son amplitude augmenter puis diminuer au cours du temps en forme de cloche facilement modélisable. Si ces deux caractéristiques sont repérées par le programme, l'unité de calcul est "marquée" et Berkeley se penchera sur votre trouvaille.
Le client graphique Seti sur Boinc
Infos complémentaires
- durée de l'unité: 3h sur un P4 à 2.8GHz
- plus de 355 000 utilisateurs sur BOINC
Le projet Einstein@home
Einstein@Home est un projet qui a été développé dans le but de rechercher des signaux venant d'étoiles extrêmement denses et en rotation rapide à partir des données fournies par "l'observatoire d'ondes gravitationnelles à interféromètre laser" LIGO aux Etats-Unis, et "l'observatoire d'ondes gravitationnelles" GEO 600 en Allemagne.
On pense que de telles étoiles sont des étoiles à quark ou à neutron, et on observe déjà une sous-catégorie de celles-ci comme les pulsars ou les objets célestes émettant des rayons-X. Les chercheurs pensent que certaines de ces étoiles compactes ne sont pas parfaitement sphériques, et si tel est le cas, elles doivent émettre des ondes gravitationnelles particulières que LIGO et GEO 600 devraient commencer à détecter.
Einstein@home (ou e@h) est un projet organisé à l'occasion de l'année mondiale de la physique (2005). C'est l'université de Milwaukee, dans le Wisconsin, qui est à l'origine du projet mais une trentaine d'universités à travers le monde y participent également. Le CALTECH (centre d'étude des nouvelles technologies) s'occupe des 2 détecteurs du LIGO aux Etats-Unis et le centre Max Planck de Hanovre s'occupe du GEO 600 en Allemagne.
GEO 600 et LIGO
Le GEO 600 est un observatoire d'ondes gravitationnelles à Hanovre (Allemagne) construit grâce à une coopération entre des scientifiques allemands et britanniques. Le LIGO est quant à lui composé de deux de ces observatoires, l'un situé à Livingston, en Louisiane, et l'autre à Hanford, état de Washington.
Ces trois observatoires distinguent des fluctuations dans la structure de l'espace-temps connues sous le nom d'ondes gravitationnelles. Les ondes sont détectées par 2 rayons laser perpendiculaires situés dans chaque installation.
Ligo Livingston et Ligo Handford
GEO 600 à Hanovre
Lorsqu'une onde gravitationnelle passe à proximité des rayons laser, elle modifie de façon infime la longueur de leur chemin à parcourir. Les scientifiques du LIGO et du GEO 600 observent les ondes gravitationnelles en analysant ces modifications de la trajectoire des rayons laser. Plus un rayon laser est long, plus la mesure de la variation de sa trajectoire est précise.
Les rayons effectuent des allers-retours entre des miroirs espacés de 600 mètres au GEO 600 et de 4km aux deux installations du LIGO, ce qui rend ces observatoires très sensibles. En effet, le LIGO devrait être capable de mesurer des modifications dans les trajectoires des rayons de l'ordre du cent millionième du diamètre de l'atome d'hydrogène.
Les ondes gravitationnelles sont des ondulations dans la structure du temps et de l'espace produites par des événements, dans notre galaxie et dans tout l'univers, tels que les collisions de trous noirs, les ondes de choc provenant de l'explosion de supernovae et des pulsars en rotation (étoiles à neutrons ou étoiles à quarks).
Ces ondulations dans la structure de l'espace-temps voyagent jusqu'à la Terre, apportant avec elles des informations sur leurs origines ainsi que des informations inestimables sur la nature de la gravité.
Albert Einstein a prédit l'existence de ces ondes gravitationnelles dans sa théorie de la relativité générale, mais ce n'est qu'actuellement, au 21ème siècle, que la technologie a suffisamment évolué pour que les scientifiques puissent les détecter et les étudier.
Bien que les ondes gravitationnelles n'aient pas encore été détectées directement, leur influence sur des pulsars binaires (2 pulsars orbitant chacun l'un autour de l'autre) a été mesurée de façon fiable, et il en a résulté qu'elles étaient parfaitement en accord avec les prédictions d'Einstein. Joseph Taylor et Rusell Hulse ont d'ailleurs remporté le prix Nobel de physique en 1993 pour leurs études dans ce domaine.
Infos complémentaires
- Les scientifiques du projet espèrent 1 Million d'utilisateurs à e@h .
- 1000 nouveaux utilisateurs par jour, projet au plus gros potentiel.
- Les unités de calcul durent environ 10H sur un P4 à 3GHz.
4 - Les projets LHC@home et Climate prediction
Le projet LHC@home
LHC@home est un projet du CERN qui vise à simuler les trajectoires de particules élémentaires dans le futur accélérateur de particules à Genève. Le CERN (Centre Européen pour la Recherche Nucléaire ) est le plus grand centre scientifique au monde dans le domaine de la physique nucléaire. En 2007, la construction de l'accélérateur de particules géant du CERN, le LHC (Large Hadron Collider), sera terminée.
Pour optimiser sa construction et sa maintenance (surtout celle des capteurs ultra-sophistiqués) le CERN a besoin de faire des simulations de grande envergure. Ces simulations permettent aux ingénieurs européens d'optimiser et d'accélérer la construction de ce qui sera le plus grand instrument scientifique au monde (27km de circonférence).
Une fois l'accélérateur de particules construit, les différents capteurs produiront 15 Po de données (pétaoctet=10^15 octet) par an ce qui constitue 10% de la production annuelle de la Terre entière.
Pour analyser ces données, le CERN envisage de faire appel au public et à BOINC, mais pas avant 2007-2008. Le programme actuel simule 100 000 tours ou 1 000 000 tours de 60 particules dans le futur LHC. Ces particules effectueraient ces tours en moins d'une seconde en réalité mais un ordinateur actuel met de 1h à 10h pour effectuer la simulation !
L'accélérateur de particules LHC
LHC va peut être enfin permettre de découvrir le célèbre boson de Higgs, qui est l'un des chaînons manquants pour approfondir la recherche fondamentale en physique nucléaire.
Climateprediction.net (CPDN) est la plus grande expérience ambitionnant d'établir une prévision du climat du 21ème siècle. Le changement climatique et nos actions pour gérer ce problème ont des répercussions à l'échelle planétaire, affectant la production agricole, les ressources en eau, les écosystèmes, la demande énergétique, l'activité économique de régions entières, entre autres.
La communauté scientifique s'accorde sur le fait que le climat va se réchauffer au cours du siècle à venir. Climate prediction pourrait, pour la première fois, nous informer sur les scénarios futurs les plus probables.
Infos complémentaires
- une unité dure 500h sur un P4 @ 3.0Ghz (elles sont très longues !). Evitez donc de mettre CPDN sur des machines de moins d'1.5GHz
- la "report deadline" (temps alloué pour envoyer les résultats finaux) est de 11 mois
5 - Le projet ProteinPredictor@home
ProteinPredictor@home est une expérience de calcul partagé dont le but est de prévoir la structure d'une protéine. L'objectif de ce travail est de tester et évaluer les nouveaux algorithmes et méthodes d'évaluation des structures de protéines.
Des tests ont été effectués dans le cadre de la sixième expérience bisannuelle de CASP (Critical Assessment of Techniques for Protein Structure Prediction), les scientifiques ont besoin à présent de poursuivre le développement et ces tests avec pour application des buts biologiques réels.
L'objectif est d'utiliser cette approche et l'énorme puissance de calcul de BOINC pour résoudre des problèmes associés aux maladies liées aux protéines.
Pourquoi la prédiction de structures de protéines ?
La mise en relation de la structure de la protéine (la disposition tridimensionnelle des fonctions chimiques faisant partie des 20 acides aminés naturels qui forment la base de tout processus chimique dans un organisme vivant) et de la séquence de la protéine (l'expression de la diversité chimique dans l'organisation moléculaire que la nature exprime dans les gènes composant le génome) est un des plus grands défis actuels pour les physiciens, les chimistes, les biologistes et les informaticiens.
Ce défi est particulièrement crucial suite aux avancées récentes dans l'analyse des gènes d'organismes complets, y compris le génome humain, pour identifier les relations de ces gènes qui commandent des processus et les réseaux cellulaires, ainsi que le lien entre la structure tridimensionnelle d'une protéine et sa fonction biochimique.
Les chercheurs ont accompli des progrès significatifs en répondant à ce défi par le développement des théories fondamentales qui décrivent le rapport entre la diversité chimique des séquences de protéine et la fonction d'énergie dictée par cette diversité.
La théorie de la fonction d'énergie fournit un cadre non seulement pour la rationalisation et la prédiction/suggestion d'expériences nouvelles et existantes mais aussi pour le développement d'algorithmes informatiques destinés à prévoir la structure de protéines inconnues en se basant uniquement sur leur séquence.
Cette action, appelée prédiction de structures de protéines, est à présent un domaine de recherche très actif réunissant des chercheurs de plusieurs horizons allant de la physique à l'informatique en passant par la biologie. L'objectif de cette activité est de développer, tester et appliquer des méthodes pour relier directement les séquences de protéines à leurs représentations tridimensionnelles.
Comment se déroule la prédiction ?
La prévision de structures de protéines s'est répandue dans toute la communauté des chercheurs en biophysique. Cependant, le travail dans ce secteur est très complexe et gourmand en ressources informatiques.
Dans un effort pour aider le développement, l'évaluation du progrès et l'examen critique de ce domaine, une action connue sous le nom d' "évaluation critique des techniques pour la prévision de structures de protéines" (CASP) a été lancée il y a environ douze ans.
Le but de cette action était de fournir des objectifs pour la prévision en aveugle de structures de protéines à la communauté des "prédicteurs" sur une base bisannuelle, et de servir de plateforme tant pour la revue de la communauté que pour la discussion sur les avancées dans les méthodes de prédiction de structures.
Le sixième exercice bisannuel CASP est à présent entamé, et beaucoup de chercheurs dans le domaine considèrent cela comme une compétition pour promouvoir les meilleures méthodes de prédiction et leurs travaux. Cette compétition implique généralement 3 à 4 mois d'effort mental (et électronique) intensif pendant l'été (mai à septembre) pour peaufiner des prévisions pour 50-70 structures inconnues de protéines.
Les résultats des prédicteurs sont analysés en automne, les structures sont publiées et les prédictions sont évaluées lors de la réunion de CASP qui suit la "saison de prédiction".
En quoi consiste le travail de prédiction ?
Une équipe de scientifiques a été réunie pour explorer les différents aspects de la prédiction de structures de protéines pour les deux CASP précédents et à nouveau pour les expérimentations en cours. Dans le passé, les efforts ont été axés sur l'algorithmique et/ou les questions scientifiques soulevées par la prédiction de structures de protéines, et les efforts ont été orientés vers des tests d'hypothèses concernant la nature du problème qu'est la prédiction. L'un des thèmes récurrents lors des essais a été l'importance de la modélisation informatique de configurations de protéines.
Pendant cette “saison CASP”, l'objectif est de s'occuper de simulations de conformation. Avec l'amélioration des méthodes, des algorithmes précédents et de l'ordre de grandeur de la puissance de calcul disponible, il est possible d'améliorer de manière significative la capacité à prédire des structures de protéines.
Pour atteindre cet objectif il a été mis en place un "supercalculateur de prédiction de structure" basé sur la plateforme BOINC: ProteinPredictor@Home.
Pourquoi et en quoi ProteinPredictor@Home est différent d'un autre projet Boinc, Folding@Home, sachant que les deux semblent avoir les mêmes objectifs ?
La prédiction de structures de protéines (Predictor) part d'une séquence d'acides aminés et tente de prédire la forme repliée et fonctionnelle de la protéine, soit sans en connaître la structure détaillée, soit par analogie avec des protéines déjà connues.
Dans le cas du pliage (Folding), les scientifiques effectuent une recherche en aveugle basée uniquement sur la séquence. La modélisation par analogie identifie tout d'abord des protéines dont la structure et certains niveaux de séquence sont identiques à la nouvelle protéine recherchée, puis construit une prédiction de celle-ci par analogie.
Les deux approches utilisent des techniques d'optimisation à plusieurs niveaux pour identifier le modèle structurel le plus approprié et se prêtent bien au calcul distribué.
Predictor@Home est le premier projet de ce type à utiliser le calcul distribué pour ce genre de prédiction de structure. La prédiction de la structure d'une protéine inconnue est un problème crucial dans la validation de médicaments basés sur ces structures, conçus pour le traitement de maladies nouvelles et existantes.
Les études de repliement de protéines et la caractérisation du processus de repliement sont basées sur les connaissances de la structure finale de la protéine repliée (dans la nature) et permettent de comprendre le processus de repliement à partir d'une chaîne de protéine non pliée. Ces études sont terminées par des comparaisons avec des protéines natives (dans la nature).
L'analyse du processus de repliement permet à des théories sur le pliage de protéines d'établir des rapports directs avec les mesures expérimentales de ce processus. Le projet Folding@Home a été un pionnier dans l'utilisation du calcul distribué pour l'étude du repliement. La compréhension du processus de repliement permet de découvrir l'origine de maladies qui découlent de problèmes lors du repliement de protéines, comme la maladie d'Alzheimer ou celle de la vache folle.
Les deux approches explorent les structures et le repliement et leurs buts sont complémentaires.
Exemples de protéines découvertes grâce à ProteinPredictor@Home
Infos complémentaires
- une unité dure environ 50 minutes sur un P4 @ 3GHz
6 - Conclusion
Plus d'information sur la plate-forme BOINC et les différents projets qui y sont intégrés sont disponibles en français sur le site de l'Equipe de la Science: lien. Vous y trouverez notamment des informations détaillées vous permettant d'installer le client BOINC et de vous inscrire sur un ou plusieurs projets (lien).
Si vous souhaitez rejoindre une team de l'alliance, sachez que l'Equipe de la science et la communauté Techno-Science.net seraient heureux de vous accueillir. Pour cela il vous suffit de vous inscrire dans la team "L'Alliance Francophone" et de faire précéder votre nom d'utilisateur par la séquence "[AF>EDLS>Techno-Science.net]".
Remerciements: pas, team-est, boincfrance et techno-science