Dans ce qui suit,
désigne le groupe symétrique à n! éléments, et
désigne une permutation, un élément typique de
Inégalité de réarrangement — Si
et si
alors
Autrement dit le maximum, sur
de l'application :
est atteint pour σ=Id. On a un résultat similaire pour le minimum de l'application :
ce qui signifie que le minimum est atteint pour σ=(n, n-1, n-2, ... , 3, 2, 1).
Si toutes les inégalités des hypothèses sont strictes, il n'y a égalité que pour σ=Id.
Applications
Il existe beaucoup d'applications plus ou moins concrètes de cette inégalité ; une de celles qui viennent à l'esprit en premier est qu'on a intérêt à avoir les meilleures notes yi dans les matières qui ont les plus gros coefficients xi.
Job-shop à une machine
On dispose d'une machine pour accomplir un ensemble de k tâches, commandées par k clients. Pour traiter la tâche n°i, la machine consomme un tempspi. La machine ne peut effectuer qu'une tâche à la fois. L'objectif est de minimiser le temps d'attente total des k clients :
où le temps d'attente du client n°m,
dépend de l'ordre σ dans lequel les tâches sont présentées à la machine (la machine traite d'abord la tâche σ(1), puis σ(2), etc ... ) :
Autrement dit, au supermarché, pour minimiser le temps total d'attente des clients, il faut faire passer en premier ceux qui ont le caddy le moins plein.
L'algorithme de tri suivant a pour but de déterminer l'appartenance d'éléments (individus) d'une suite à un ensemble de k catégories C1 , C2 , ... , Ck disjointes, à des fins d'indexation ou de rangement :
[10] i = 1 ; u = 0 [20] Enregistrer l'individuw [30] Tant que u = 0, faire: [40] Si
ranger w dans le fichierFi et faire u = 1 [50] i = i+1 [60] Fin tant [70] Fin
Notons X(w) le numéro de la catégorie à laquelle appartient l'individu w et T(w) le temps nécessaire à l'algorithme pour ranger w. On se convainc facilement que T est une fonction affine croissante de X (posons T = aX + b, a>0) : en effet, la boucle tant que est itérée m fois si l'individu appartient à la catégorie Cm.
On suppose que
les individus
traités par l'algorithme sont tirés au hasard dans une population divisée en k catégories disjointes C1 , C2 , ... , Ck ;
au départ la numérotation des catégories peut-être choisie librement : on peut choisir de tester l'appartenance de l'individu d'abord à
puis à
etc ... où σ désigne une permutation du groupe symétrique choisie une bonne fois pour toutes avant le traitement de la suite
;
la proportion d'individus de catégorie Ci dans la population est pi .
Le coût total C(ω) de l'exécution de l'algorithme est donné par
où
est l'espérance de la variable aléatoireX. Le développement asymptotique de c(ω) découle de la loi forte des grands nombres, si l'on suppose que les individus sont tirés de la population avec remise. Le terme o(n) peut être précisé en
en utilisant, par exemple, le théorème central limite, ou bien l'inégalité de Hoeffding.
L'inégalité de réarrangement (et le bon sens) disent que, dans un but d'économie, il est optimal de choisir une permutation σ satisfaisant à :
Interprétation :
Autrement dit, il est optimal, lorsqu'on teste l'appartenance aux différentes catégories, de ranger ces catégories dans l'ordre d'importance décroissante.
Par exemple le coût le plus défavorable (resp. le plus favorable), si n = 3 et {p1 , p2 , p3 } = {0.1 ; 0.6 ; 0.3}, correspond à 132 et donne
(resp. correspond à 231 et donne
).
Inégalité de Tchebychev pour les sommes
L'inégalité de Tchebychev pour les sommes est due à Pafnouti Tchebychev. Elle découle directement de l'inégalité de réarrangement, et est un cas particulier de l'inégalité FKG ou inégalité de corrélation. Elle ne doit pas être confondue avec l'inégalité de Bienaymé-Tchebychev.
Inégalité de Tchebychev pour les sommes — Si
et
alors
De même, si
et
alors
Distance de Wasserstein L2
Un problème analogue, en probabilités, est de trouver les extrémas de la quantité lorsque la loi jointe du couple (X,Y) est arbitraire, ainsi, d'ailleurs, que l'espace probabilisé sur lequel X et Y sont définies, alors que les marginales (les lois de probabilités des deux variables aléatoires X et Y), disons μ et ν, sont fixées. La solution évoque celle de l'inégalité de réarrangement, puisque le maximum est atteint, entre autres, par les deux applications croissantes X0 et Y0 définies sur
à l'aide du théorème de la réciproque : pour
on pose
Le minimum étant atteint, lui, pour le choix conjoint de X0 et Y1 , où, pour
on pose
Remarque :
Hardy, Littlewood, et Polya appellent X0 et Y0 les réarrangées croissantes de μ et ν. De la même manière, Y1 est une réarrangée décroissante de ν.
A égalité presque sûre près, X0 et Y0 sont les seules applications croissantes définies sur
et ayant pour lois de probabilités respectives μ et ν, Y1 étant la seule application décroissante définie sur
et ayant pour loi de probabilité ν ...
Définition — La distance de Wasserstein L2entre les deux lois de probabilitéμetν est l'infimum des quantités
lorsque les lois de probabilités respectives des deux variables aléatoires X et Y sont fixées égales à μ et ν, respectivement, mais que la loi jointe du couple (X,Y) est arbitraire, ainsi, d'ailleurs, que l'espace probabilisé
sur lequel X et Y sont définies.
Comme
ne dépend pas de la loi jointe, mais seulement de μ, ce problème de minimisation de
est équivalent au problème précédent (de maximisation de
), pour peu que
et
soient toutes deux finies.
Le problème du calcul de la distance de Wasserstein L2 entre deux lois de probabilités est une variante du problème de transport de Monge-Kantorovitch.














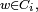

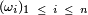
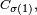
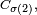
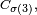
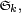
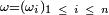






![\begin{align} c(\omega)&= \sum_{i=1}^n T(\omega_{i})\\ &= bn+a\sum_{i=1}^n X(\omega_{i})\\ &= bn+an\mathbb{E}[X]+o(n),\\ \end{align}](https://static.techno-science.net/illustrationWebp/Definitions/autres/3/3b34fd5bd76497d5f0565bbec1f91b90_9e4e86752761fce07f1ccb894fa5dbb5.png)
![\mathbb{E}[X]=\sum_{m=1}^k p_{\sigma(k)}k](https://static.techno-science.net/illustrationWebp/Definitions/autres/3/3bb90ce87b5f4c8e0fcdee7c2e19f5c0_e2c4353ba4d476efd4ecfabdeac64af5.png)


![\scriptstyle\ \mathbb{E}[X]{{=}}2.5, \](https://static.techno-science.net/illustrationWebp/Definitions/autres/6/6bd0ec38f09c790db72f90aa59e7d74b_d19be4ef88047a3319d3596741d60756.png)
![\scriptstyle\ \mathbb{E}[X]{{=}}1.5 \](https://static.techno-science.net/illustrationWebp/Definitions/autres/2/26bcfca19da4190b5b70e2b2e52e3d44_a75db578d9435ea4d3a6c218a682408b.png)





![\scriptstyle\ \mathbb{E}[XY]\](https://static.techno-science.net/illustrationWebp/Definitions/autres/c/c3bb79ea88b1fbeb52576f109f9ac1fb_a9f26358d16842e0c7fe4639b0836dd7.png)

![\scriptstyle\ (\Omega, \mathcal{A}, \mathbb{P})=(]0,1[,\mathcal{B}(]0,1[), dx)\](https://static.techno-science.net/illustrationWebp/Definitions/autres/e/e5f621136a6756de23c4d44805701352_92b8d073a82d99875c0f9953ba5aa92c.png)
![\ \scriptstyle \omega \in]0,1[,\](https://static.techno-science.net/illustrationWebp/Definitions/autres/7/74fc27ca681c581512ca0a341b4d9f15_4821e3722d4ced243a608ae390cf3571.png)
![\begin{align} X_0(\omega)&= \inf\left\{x\in\mathbb{R}\ |\ \mu(]-\infty, x])\ge\omega\right\}, \\ Y_0(\omega)&= \inf\left\{x\in\mathbb{R}\ |\ \nu(]-\infty, x])\ge\omega\right\}. \end{align}](https://static.techno-science.net/illustrationWebp/Definitions/autres/7/7ecaede91b721941248a685e2f125b40_8004344fab3bd7b21b2fed70aef80a00.png)

![\sqrt{\mathbb{E}\left[\left(X-Y\right)^2\right]}\ =\ \sqrt{\mathbb{E}\left[X^2\right]+\mathbb{E}\left[Y^2\right]-2\mathbb{E}\left[XY\right]},](https://static.techno-science.net/illustrationWebp/Definitions/autres/2/2e99ccda347cf416f85f4ce1f697d37b_1a38b74a9fe4b585c2b886d6f754f206.png)
![\mathbb{E}\left[X^2\right]=\int_{\mathbb{R}}\ x^2\ \mu(dx)](https://static.techno-science.net/illustrationWebp/Definitions/autres/f/fde11eba0f274767e96e6c04ab720ec5_ba87b38bbe88507ea152e5d3faaf47d9.png)
![\scriptstyle\ \mathbb{E}\left[\left(X-Y\right)^2\right]](https://static.techno-science.net/illustrationWebp/Definitions/autres/2/214a8e9d32a5095985c7eaa576edc90a_23436368cdf85e362c83f345efd1afb9.png)
![\scriptstyle\ \mathbb{E}\left[XY\right]\](https://static.techno-science.net/illustrationWebp/Definitions/autres/0/06c3e820153eaa6ba579339f520b8b01_8b32b0928f7ed13161c90dbee2b081eb.png)
![\scriptstyle\ \mathbb{E}\left[X^2\right]=\int_{\mathbb{R}}\ x^2\ \mu(dx)](https://static.techno-science.net/illustrationWebp/Definitions/autres/8/843ae6cac649befbe90ddf21efe62c04_e2583d95339b975dfea9befb4c323681.png)
![\scriptstyle\ \mathbb{E}\left[Y^2\right]=\int_{\mathbb{R}}\ x^2\ \nu(dx)](https://static.techno-science.net/illustrationWebp/Definitions/autres/a/aa1bf110f4c3558469b23880cf6c069c_ce12be13b896110de5b4b26bf8c6b720.png)

















































