Parallélisme (informatique) - Définition
La liste des auteurs de cet article est disponible ici.
Mécanisme sous-jacent au parallélisme
Plusieurs mécanismes ont été mis en place pour permettent d'exécuter des programmes en utilisant le paradigme du parallélisme. Certains sont liés à la création d'algorithmes parallèles, d'autres sont matériels.
Le Parallélisme au sein du processeur
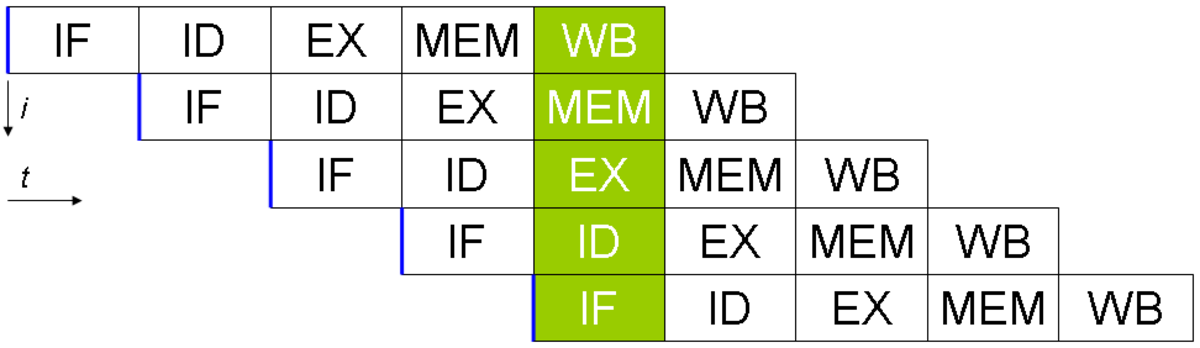
Un programme informatique est, par essence, un flux d'instructions exécuté par un processeur. Chaque instruction nécessite plusieurs cycles d'horloge, l'instruction est exécuté par autant d'étape que de cycle nécessaire. Les microprocesseurs séquentiels exécutent l'instruction suivante lorsqu'ils ont terminé la première. Dans le cas du parallélisme d'instruction, le microprocesseurs peut traiter plusieurs de ces étapes en même temps, pour plusieurs instructions différentes car elles ne mobilisent pas les mêmes ressources internes. Autrement dit, le processeur exécute en parallèle des instructions qui se suivent à différents stades d'achèvement. Cette files d'exécution s'appelle une pipeline. Ce mécanisme a été implémenté la première fois dans les années 1960 par IBM.
Les processeurs plus évolués exécutent en même temps autant d'instructions qu'ils ont de pipelines, à la condition que les instructions de tous les étages soient indépendantes c'est-à-dire que l'exécution de chacune ne modifie pas le résultat du calcul d'une autre. Les processeurs de ce types sont appelés superscalaires. Le premier ordinateur à être équipé de ce type de processeur était le Seymour Cray CDC 6600 en 1965. L'Intel Pentium est le premier des processeurs superscalaires pour compatible PC. Ce type de processeur s'est imposé pour les machines grand public à partir des années 1980 et jusqu'aux années 1990.
L'exemple canonique de ce type de pipeline est celui d'un processeur RISC, en cinq étapes. L'Intel Pentium 4 dispose de 35 étages de pipeline. Un compilateur optimisé pour ce genre de processeur fournira un code plus rapide.
Aujourd'hui, les concepteurs de processeur ne cherchent pas simplement à exécuter plusieurs instructions indépendantes en même temps, ils cherchent à optimiser le temps d'exécution de l'ensemble des instructions. Par exemple le processeur peut trier les instructions de manière à ce que tous ces étages contiennent des instructions indépendantes. Ce mécanisme développé par IBM s'appelle l'exécution out-of-order.
Pour éviter une perte de temps liée à l'attente de nouvelles instructions et surtout le délais de rechargement du contexte entre chaque changement de threads, les fondeurs ont ajouté à leurs processeurs des techniques pour que les threads puissent partager les pipelines, caches et registres. Cette technique, appelée Simultaneous Multi Threading, a été mise au point dans les années 1950. Par contre, pour obtenir une accélération, les compilateurs doivent prendre en compte cette spécificité, il faut donc recompiler les programmes pour ces types de processeurs. Intel a commencé à produire, début des années 2000, des processeurs de technologie SMT à deux voies. Ces processeurs, les Xeon, peuvent exécuter simultanément deux Threads qui partagent les mêmes Pipelines, caches et registres. Intel a appelé sa technologie SMT à deux voies : l’Hyperthreading. Le Super-threading est une technologie SMT où plusieurs threads partagent aussi les mêmes ressources, mais ces threads ne s'exécutent que l'un après l'autre et non pas en même temps.
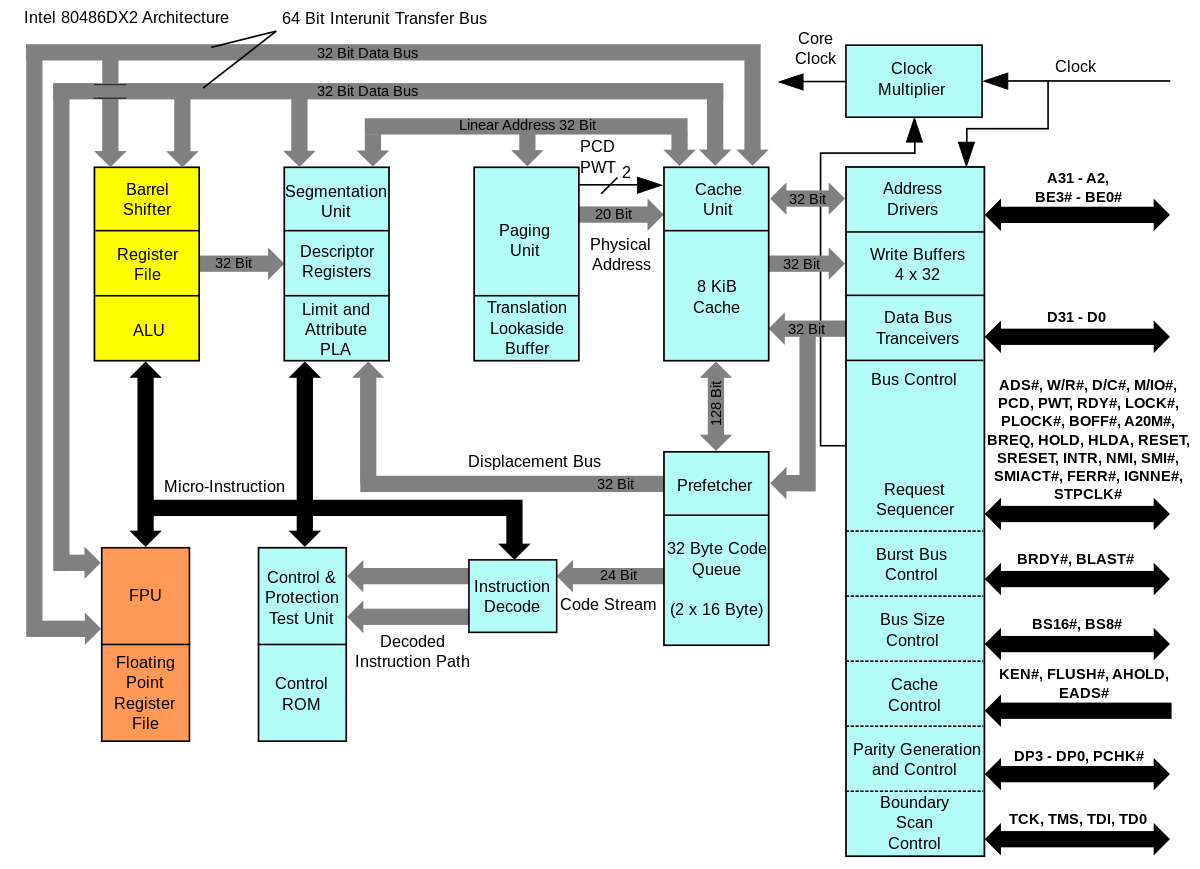
Depuis longtemps déjà, existait l'idée de faire cohabiter plusieurs processeurs au sein du même composant comme par exemple les System on Chip. Cela consistait par exemple à ajouter au processeur, un coprocesseur arithmétique, un DSP, un contrôleur comme celui qui gère l'HyperTransport pour les x86 à partir de l'Opteron d'AMD en 2003, voir un cache mémoire ou même à l'intégralité des composants que l'on trouve sur une carte mère. Le premier processeur de la gamme x86 a intégré un Flotting processor unit est le 486 DX début 1989. Des processeurs utilisant deux ou quatre cœurs, pas forcément symétrique comme les cell, sont donc apparus comme par exemple le POWER4 d'IBM sorti en 2001. Ils disposent des technologies citées préalablement. Les ordinateurs qui disposent de ce type de processeurs coutent moins cher que les ordinateurs qui disposent de plusieurs processeurs, cependant en comparaison, les performances sont plus ou moins honorable en fonction du type de problème traité. Si, en comparaison d'un système à multiprocesseur, le partage du cache favorise la vitesse, le partage du bus mémoire en revanche la diminue. Des API spécialisées ont été développées afin de tirer parti au mieux de cette technologie, comme le Threading Building Blocks d'Intel.
Les systèmes à plusieurs processeurs

|
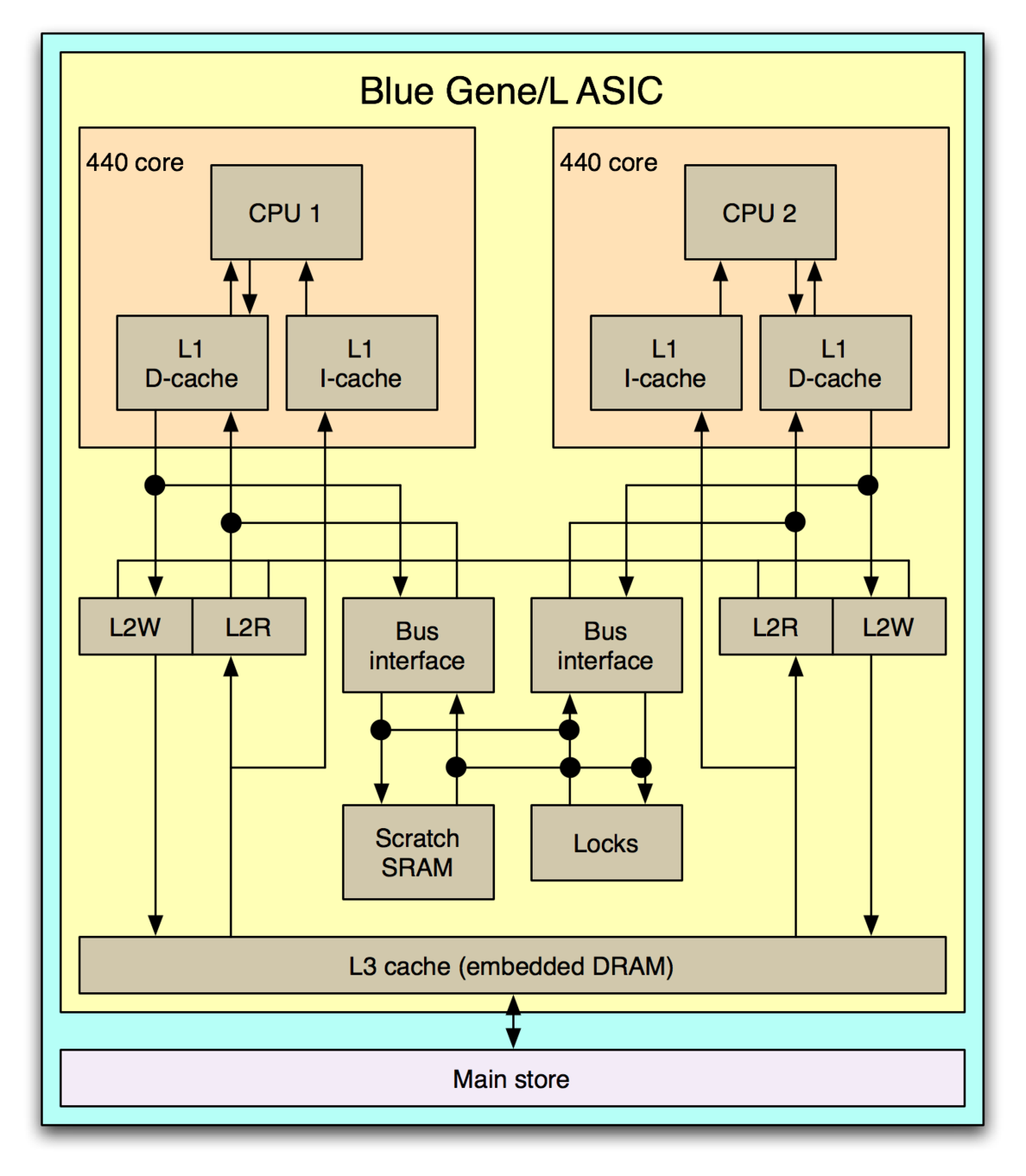
| |
| Le Blue Gene L disposent seize cartes-nœuds (à gauche) pour un total de 440 cœurs organisés suivant le schéma de droite | ||
L'idée de faire cohabité deux processeurs dans la même machine date également des années 1960, le D825 de Burroughs Corporation commercialisé en 1962 est le premier ordinateur multi-processeur, mais ce système n'était pas parallèle. Il a fallu attendre 1969 pour que Honeywell produise le premier ordinateur qui dispose de processeurs fonctionnent réellement en parallèle. Les huit processeurs de cette machine de la série Honeywell 800 fonctionnait de manière symétrique (ou SMP), c'est-à-dire que tous les processeurs ont la même fonction et les mêmes capacités. Ce ne fut pas le cas de toutes les machines, DEC et le MIT ont développé dans les années 1970 une technologie asymétrique, mais elle a été abandonné dans les années 1980. Peut de machine ont utilisé ce principe, même si certaines ont eu du succès comme les VAX.
Dans un système symétrique les processeurs se synchronisent et échange des données via un bus.Historiquement, ces systèmes étaient limités à 32 processeurs, en effet au delà, les contentions de bus deviennent ingérables. Cependant « Grâce à la petite taille des processeurs et à la réduction significative des exigences en bande passante du bus obtenue par la taille importante des caches, les systèmes à multiprocesseurs symétriques sont d'un excellent rapport coût-efficacité, à condition toutefois qu'il existe une une bande passante mémoire suffisante ». Ainsi les solutions comme par exemple les architectures NUMA. NUMA est un système où les zones mémoires sont accessibles par l'intermédiaire de différents bus, c'est-à-dire que chaque zone mémoire est réservée à un ou quelques processeurs seulement et que les données qui y sont stockées ne sont disponibles que via un passage de message analogue à celui mis en place pour les mémoires distribuées. Dans tous les cas, les temps d'accès diffèrent en fonction des processeurs et des zones mémoires visées. Ce système peut être vue comme une étape entre le SMP et le clustering.
Système à plusieurs machines
Les machines du TOP500 sont des machines de ce type.

















































