Propriété de Markov - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
En probabilité, un processus stochastique vérifie la propriété de Markov si et seulement si la distribution conditionnelle de probabilité des états futurs, étant donné les états passés et l'état présent, ne dépend en fait que de l'état présent et non pas des états passés (absence de « mémoire »). Un processus qui possède cette propriété est appelé processus de Markov. Pour de tels processus, la meilleure prévision qu'on puisse faire du futur, connaissant le passé et le présent, est identique à la meilleure prévision qu'on puisse faire du futur, connaissant uniquement le présent : si on connait le présent, la connaissance du passé n'apporte pas d'information supplémentaire utile pour la prédiction du futur.
Propriété de Markov faible (temps discret, espace discret)
Définition
C'est la propriété caractéristique d'une chaîne de Markov : en gros, la prédiction du futur à partir du présent n'est pas rendue plus précise par des éléments d'information supplémentaires concernant le passé, car toute l'information utile pour la prédiction du futur est contenue dans l'état présent du processus. La propriété de Markov faible possède plusieurs formes équivalentes qui reviennent toutes à constater que la loi conditionnelle de



Propriété de Markov faible « élémentaire » — Pour tout



On suppose le plus souvent les chaînes de Markov homogènes, i.e. on suppose que le mécanisme de transition ne change pas au cours du temps. La propriété de Markov faible prend alors la forme suivante :


Cette forme de la propriété de Markov faible est plus forte que la forme précédente, et entraîne en particulier que

Dans la suite de l'article on ne considèrera que des chaînes de Markov homogènes. Pour une application intéressante des chaînes de Markov non homogènes à l'optimisation combinatoire, voir l'article Recuit simulé.
La propriété de Markov faible pour les chaînes de Markov homogènes a une autre forme, beaucoup plus générale que la précédente, mais pourtant équivalente à la précédente :
Propriété de Markov faible « générale » — Pour n'importe quel choix de


Notons que les évènements passés






Si



![\scriptstyle\ p\in]0,1[.\](https://static.techno-science.net/illustrationWebp/Definitions/autres/c/c287d015f4d34a5c5b9106375fc9caaf_edb51b540783c4a76899d62cd69051f2.png)

alors qu'on peut facilement trouver



Ainsi, du fait d'une connaissance imprécise (

Pourtant, la marche aléatoire sur
Il existe une , liée à la notion de temps d'arrêt : cette propriété de Markov forte est cruciale pour la démonstration de résultats importants (divers critères de récurrence, loi forte des grands nombres pour les chaînes de Markov).
Indépendance conditionnelle
La propriété de Markov faible « générale » entraine que
Indépendance conditionnelle — Pour n'importe quel choix de


Cette égalité exprime l'indépendance conditionnelle entre le passé et le futur, sachant le présent (sachant que

Indépendance conditionnelle et homogénéité — Pour n'importe quel choix de

Critère
Critère fondamental — Soit une suite







et supposons que la suite



Petit Pierre fait la collection des portraits des onze joueurs de l'équipe nationale de football, qu'il trouve sur des vignettes à l'intérieur de l'emballage des tablettes de chocolat Cémoi ; chaque fois qu'il achète une tablette il a une chance sur 11 de tomber sur le portrait du joueur n°

![\scriptstyle\ X_{n}\in\mathcal{P}([\![ 1,11]\!])\](https://static.techno-science.net/illustrationWebp/Definitions/autres/a/a724e9ac3370b700a53a33ea3da4024f_c5fc75e6f800b3960e6d04010d5167aa.png)

![\scriptstyle\ F=[\![1,11]\!],\ E=\mathcal{P}(F),\ f(x,y)=x\cup\{y\},\](https://static.techno-science.net/illustrationWebp/Definitions/autres/3/372498e85e6edf20771a7d7b8b861881_1c12d5c29698fb07cf9343eb733131fb.png)

où les variables aléatoires

![\scriptstyle\ [\![1,11]\!]\](https://static.techno-science.net/illustrationWebp/Definitions/autres/e/e76ea9e4de780d45f1e611b71c61ffb5_544a2def4e5601588348cdefb4b3b19f.png)




- La propriété de Markov découle de l'indépendance des
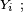
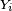
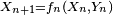
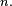
- Le critère est fondamental en cela que toute chaîne de Markov homogène peut être simulée exactement via une récurrence de la forme
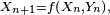
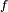
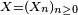
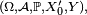
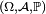
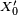
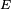
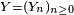
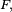
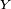
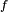
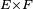
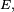
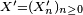













-
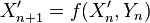
- ait même loi que la suite
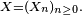


- On peut même choisir
![\scriptstyle\ F=[0,1],\](https://static.techno-science.net/illustration/Definitions/autres/e/ec112d58275f3bfdad8c05658666a1cd_1ee3f81097be3b8694f003045c9f52df.png)
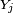
![\scriptstyle\ F=[0,1],\](https://static.techno-science.net/illustrationWebp/Definitions/autres/e/ec112d58275f3bfdad8c05658666a1cd_1ee3f81097be3b8694f003045c9f52df.png)


















































