Réseau de neurones artificiels - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
Un réseau de neurones artificiels est un modèle de calcul dont la conception est très schématiquement inspirée du fonctionnement des neurones biologiques.
Les réseaux de neurones sont généralement optimisés par des méthodes d’apprentissage de type probabiliste, en particulier bayésiens. Ils sont placés d’une part dans la famille des applications statistiques, qu’ils enrichissent avec un ensemble de paradigmes permettant de générer des classifications rapides (réseaux de Kohonen en particulier), et d’autre part dans la famille des méthodes de l’intelligence artificielle auxquelles ils fournissent un mécanisme perceptif indépendant des idées propres de l'implémenteur, et fournissant des informations d'entrée au raisonnement logique formel.
En modélisation des circuits biologiques, ils permettent de tester quelques hypothèses fonctionnelles issues de la neurophysiologie, ou encore les conséquences de ces hypothèses pour les comparer au réel.
Historique
Les réseaux neuronaux sont construits sur un paradigme biologique, celui du neurone formel (comme les algorithmes génétiques le sont sur la sélection naturelle). Ces types de métaphores biologiques sont devenues courantes avec les idées de la cybernétique et biocybernétique. Celui-ci ne prétend pas davantage décrire le cerveau qu'une aile d'avion, par exemple, copier celle d'un oiseau. En particulier le rôle des cellules gliales n'est pas simulé pour le moment (2010).
Les neurologues Warren McCulloch et Walter Pitts publièrent dès la fin des années 1950 les premiers travaux sur les réseaux de neurones, avec un article fondateur : What the frog’s eye tells to the frog’s brain. Ils constituèrent ensuite un modèle simplifié de neurone biologique communément appelé neurone formel. Ils montrèrent que des réseaux de neurones formels simples peuvent théoriquement réaliser des fonctions logiques, arithmétiques et symboliques complexes.
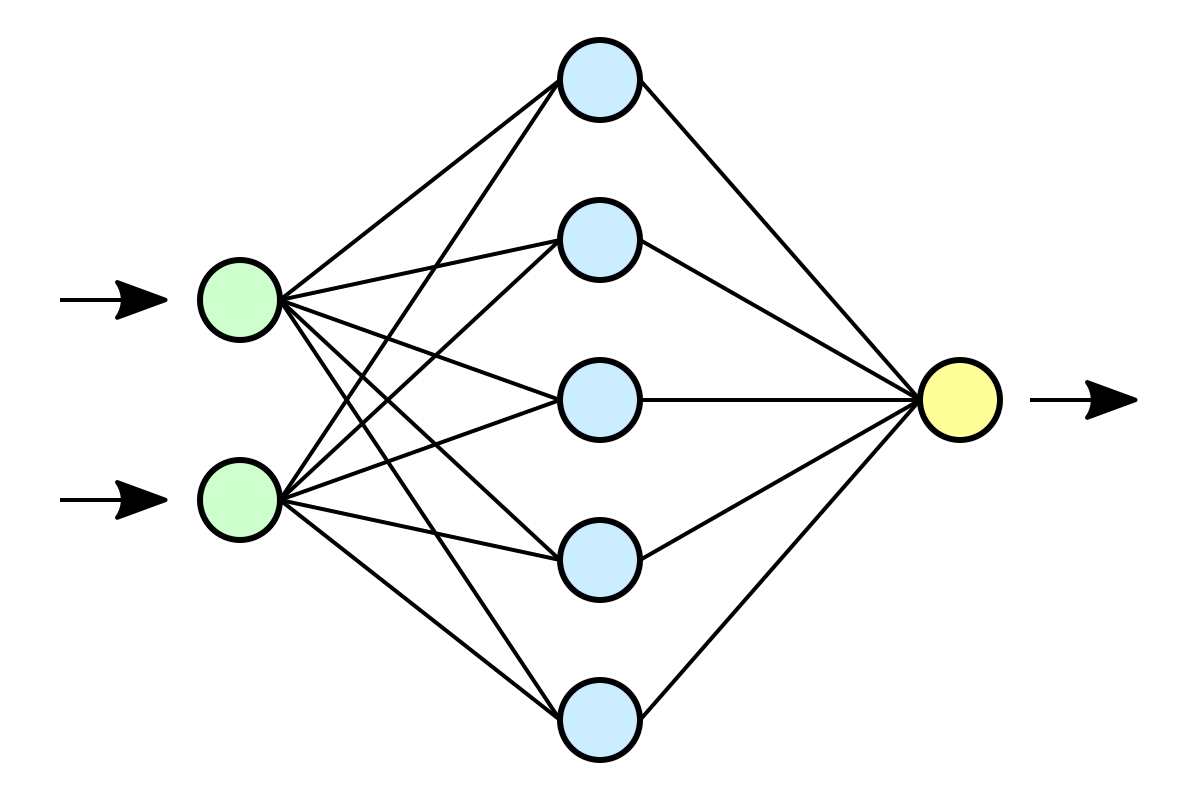
Le neurone formel est conçu comme un automate doté d'une fonction de transfert qui transforme ses entrées en sortie selon des règles précises. Par exemple, un neurone somme ses entrées, compare la somme résultante à une valeur seuil, et répond en émettant un signal si cette somme est supérieure ou égale à ce seuil (modèle ultra-simplifié du fonctionnement d'un neurone biologique). Ces neurones sont par ailleurs associés en réseaux dont la topologie des connexions est variable : réseaux proactifs, récurrents, etc. Enfin, l'efficacité de la transmission des signaux d'un neurone à l'autre peut varier : on parle de « poids synaptique », et ces poids peuvent être modulés par des règles d'apprentissage (ce qui mime la plasticité synaptique des réseaux biologiques).
Une fonction des réseaux de neurones formels, à l’instar du modèle vivant, est d'opérer rapidement des classifications et d'apprendre à les améliorer. À l’opposé des méthodes traditionnelles de résolution informatique, on ne doit pas construire un programme pas à pas en fonction de la compréhension de celui-ci. Les paramètres importants de ce modèle sont les coefficients synaptiques et le seuil de chaque neurone, et la façon de les ajuster. Ce sont eux qui déterminent l'évolution du réseau en fonction de ses informations d'entrée. Il faut choisir un mécanisme permettant de les calculer et de les faire converger si possible vers une valeur assurant une classification aussi proche que possible de l'optimale. C’est ce qu'on nomme la phase d’apprentissage du réseau. Dans un modèle de réseaux de neurones formels, apprendre revient donc à déterminer les coefficients synaptiques le moins mal adaptés à classifier les exemples présentés.
Les travaux de McCulloch et Pitts n’ont pas donné d’indication sur une méthode pour adapter les coefficients synaptiques. Cette question au cœur des réflexions sur l’apprentissage a connu un début de réponse grâce aux travaux du physiologiste canadien Donald Hebb sur l’apprentissage en 1949 décrits dans son ouvrage The Organization of Behaviour. Hebb a proposé une règle simple qui permet de modifier la valeur des coefficients synaptiques en fonction de l’activité des unités qu’ils relient. Cette règle aujourd’hui connue sous le nom de « règle de Hebb » est presque partout présente dans les modèles actuels, même les plus sophistiqués.
À partir de cet article, l’idée se sema au fil du temps dans les esprits, et elle germa dans l’esprit de Franck Rosenblatt en 1957 avec le modèle du perceptron. C’est le premier système artificiel capable d’apprendre par expérience, y compris lorsque son instructeur commet quelques erreurs (ce en quoi il diffère nettement d’un système d’apprentissage logique formel). D’autres travaux marquèrent également le domaine, comme ceux de Donald Hebb en 1949.
En 1969, un coup grave fut porté à la communauté scientifique gravitant autour des réseaux de neurones : Marvin Lee Minsky et Seymour Papert publièrent un ouvrage mettant en exergue quelques limitations théoriques du Perceptron, et plus généralement des classifieurs linéaires, notamment l’impossibilité de traiter des problèmes non linéaires ou de connexité. Ils étendirent implicitement ces limitations à tous modèles de réseaux de neurones artificiels. Paraissant alors dans une impasse, la recherche sur les réseaux de neurones perdit une grande partie de ses financements publics, et le secteur industriel s’en détourna aussi. Les fonds destinés à l’intelligence artificielle furent redirigés plutôt vers la logique formelle et la recherche piétina pendant dix ans. Cependant, les solides qualités de certains réseaux de neurones en matière adaptative, (e.g. Adaline), leur permettant de modéliser de façon évolutive des phénomènes eux-mêmes évolutifs les amèneront à être intégrés sous des formes plus ou moins explicites dans le corpus des systèmes adaptatifs, utilisés dans le domaine des télécommunications ou celui du contrôle de processus industriels.
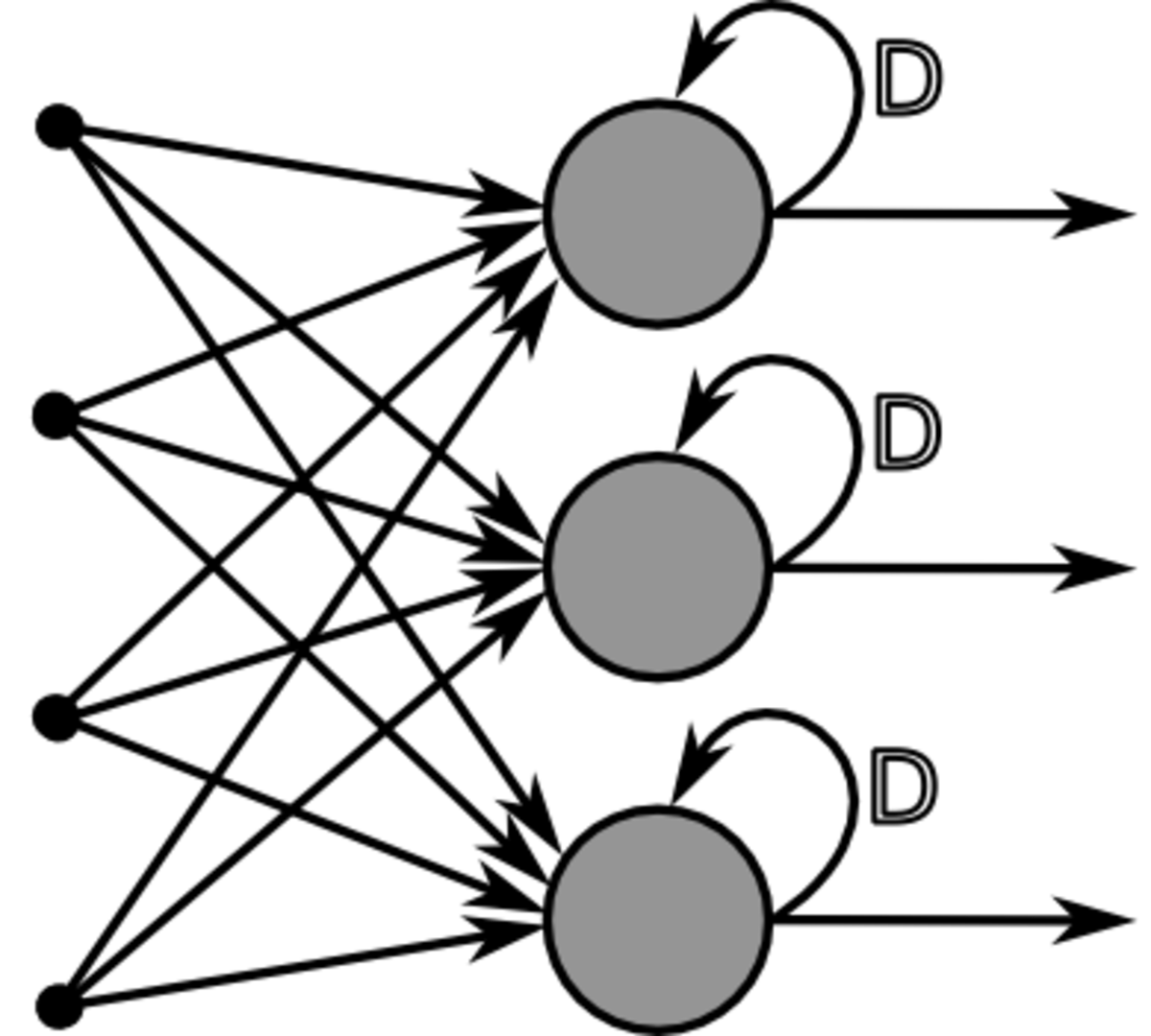
En 1982, John Joseph Hopfield, physicien reconnu, donna un nouveau souffle au neuronal en publiant un article introduisant un nouveau modèle de réseau de neurones (complètement récurrent). Cet article eut du succès pour plusieurs raisons, dont la principale était de teinter la théorie des réseaux de neurones de la rigueur propre aux physiciens. Le neuronal redevint un sujet d’étude acceptable, bien que le modèle de Hopfield souffrît des principales limitations des modèles des années 1960, notamment l’impossibilité de traiter les problèmes non-linéaires.
À la même date, les approches algorithmiques de l’intelligence artificielle furent l’objet de désillusion, leurs applications ne répondant pas aux attentes. Cette désillusion motiva une réorientation des recherches en intelligence artificielle vers les réseaux de neurones (bien que ces réseaux concernent la perception artificielle plus que l’intelligence artificielle à proprement parler). La recherche fut relancée et l’industrie reprit quelque intérêt au neuronal (en particulier pour des applications comme le guidage de missiles de croisière). En 1984 (?), c’est le système de rétropropagation du gradient de l’erreur qui est le sujet le plus débattu dans le domaine.
Une révolution survient alors dans le domaine des réseaux de neurones artificiels : une nouvelle génération de réseaux de neurones, capables de traiter avec succès des phénomènes non-linéaires : le perceptron multicouche ne possède pas les défauts mis en évidence par Marvin Minsky. Proposé pour la première fois par Werbos, le Perceptron Multi-Couche apparait en 1986 introduit par Rumelhart, et, simultanément, sous une appellation voisine, chez Yann le Cun. Ces systèmes reposent sur la rétropropagation du gradient de l’erreur dans des systèmes à plusieurs couches, chacune de type Adaline de Bernard Widrow, proche du Perceptron de Rumelhart.
Les réseaux de neurones ont par la suite connu un essor considérable, et ont fait partie des premiers systèmes à bénéficier de l’éclairage de la théorie de la « régularisation statistique » introduite par Vladimir Vapnik en Union soviétique et popularisée en occident depuis la chute du mur. Cette théorie, l’une des plus importantes du domaine des statistiques, permet d’anticiper, d’étudier et de réguler les phénomènes liés au sur-apprentissage. On peut ainsi réguler un système d’apprentissage pour qu’il arbitre au mieux entre une modélisation pauvre (exemple : la moyenne) et une modélisation trop riche qui serait optimisée de façon illusoire sur un nombre d’exemples trop petit, et serait inopérant sur des exemples non encore appris, même proches des exemples appris. Le sur-apprentissage est une difficulté à laquelle doivent faire face tous les systèmes d’apprentissage par l’exemple, que ceux-ci utilisent des méthodes d’optimisation directe (e.g. régression linéaire), itératives (e.g., l'algorithme du gradient), ou itératives semi-directes (gradient conjugué, espérance-maximisation...) et que ceux-ci soient appliqués aux modèles statistiques classiques, aux modèles de Markov cachés ou aux réseaux de neurones formels.

















































