Exploration de données - Définition
La liste des auteurs de cet article est disponible ici.
Projet, Méthodes et Processus
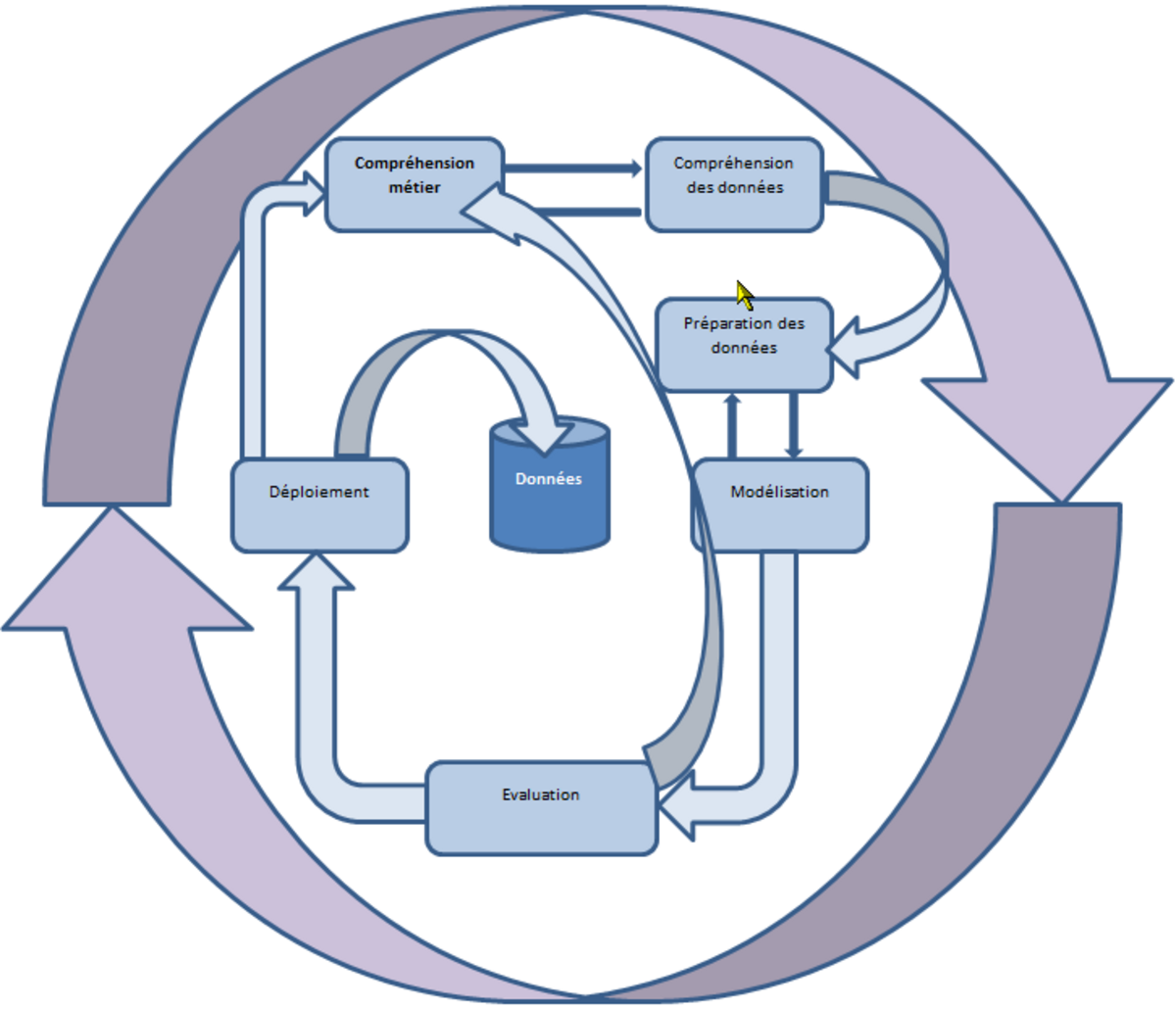
De «bonnes pratiques» ont émergé au fil du temps pour améliorer la qualité des projets. Parmi celles-ci, les méthodologies aident les équipes à organiser les projets en processus. Au nombre des méthodes les plus utilisées on trouve la méthodologie SEMMA du SAS Institute et la CRISP-DM qui est la méthode la plus employée. Techniquement, la méthode CRISP-DM découpe le processus de data mining en six étapes permettant de structurer la technique et de l'ancrer dans un processus industriel. Plus qu'une théorie normalisée, c'est un processus d'extraction des connaissances métiers comportant les étapes principales suivantes :
- Comprendre le métier - Formaliser un problème que l'organisation cherche à résoudre en termes de données, et mettre en place un plan initial pour réaliser cet objectif.
- Comprendre les données - Accéder aux données appropriées quelles qu'elles soient
- Préparer ces données en vue des traitements et utilisations futurs
- Modéliser les données en leur appliquant des algorithmes d'analyse
- Évaluer et valider les connaissances ainsi extraites des analyses
- Déployer les analyses dans l'entreprise pour une utilisation effective
Vocabulaire
Avant d'aborder la méthode CRISP-DM en détail, il est intéressant de préciser le vocabulaire rencontré dans la littérature française et anglo-saxone. Voici un tableau emprunté à Stéphane Tufféry.
|
Détailler la méthode CRISP-DM
Les principales étapes de la démarche sont expliquées ci-après.
Comprendre le métier
C'est définir le problème : le chef de projet doit comprendre les objectifs du métier en matière de DM et connaître les critères de réussite du projet.
Comprendre les données
Une fois que l'équipe de projet sait ce qu'il faut faire, elle doit se mettre en quête des données, des textes, et tout ce qui lui permettra de répondre au problème. Il lui faut ensuite en évaluer la qualité, découvrir les premiers schémas apparents pour émettre des hypothèses sur les modèles cachés.
Préparer
Le data mining se propose d'utiliser un ensemble d'algorithmes issus de disciplines scientifiques diverses (statistiques, intelligence artificielle, base de données) pour construire des modèles à partir des données, c'est-à-dire trouver des schémas « intéressants » (des patterns ou motifs selon des critères fixés au départ), et d'en extraire un maximum de connaissances utiles à l'entreprise. Les données que l'équipe de projet a collectées sont hétérogènes. Elles doivent être préparées en fonction des algorithmes utilisés, en supprimant les valeurs aberrantes - valeurs extrêmes -, en complétant les données non renseignées(par la moyenne ou en utilisant la méthode des K plus proches voisins), en supprimant les doublons, les variables invariantes et celles ayant trop de valeurs manquantes, ou bien par exemple en discrétisant les variables si l’algorithme à utiliser le nécessite, comme c'est par exemple le cas pour l'analyse des correspondances multiples (ACM), l'analyse discriminante DISQUAL, ou bien la méthode de Condorcet.
Modéliser
Une fois que les données sont prêtes à être traitées il faut les explorer. L'activité Modéliser regroupe quatre classes de tâches pouvant être utilisées seules ou en complément avec les autres :
- La Segmentation - est la tâche consistant à découvrir des groupes et des structures au sein des données qui sont d'une certaine façon «similaires», sans utiliser des structures connues dans les données.
- La Classification - est la tâche de généralisation des structures connues pour les appliquer à des données nouvelles. Par exemple, un programme d'email pourrait tenter de classer un email en tant que légitime ou bien en tant que spam. Les algorithmes généralement utilisés incluent les arbres de décision, les plus proches voisins, la Classification naïve bayesienne, les réseaux neuronaux, et les séparateurs à vaste marge (SVM).
- La Prédiction - qui tente de trouver une fonction modélisant les données avec le plus petit taux d'erreur, afin d'en prédire les valeurs futures.
- L'Association - recherche les relations entre les variables. Par exemple un supermarché peut rassembler des données sur des habitudes d'achats de ses clients. En utilisant l'apprentissage des règles d'association, le supermarché peut déterminer quels produits sont fréquemment achetés ensemble et ainsi utiliser cette connaissance à des fins de marketing. On se réfère souvent à cette technique sous le nom de « analyse du panier de la ménagère ».
Évaluer
Il s'agit d'évaluer les résultats obtenus en fonction des critères de succès du métier, d'évaluer le processus lui-même pour faire apparaître les manques et les étapes négligées. A la suite de ceci, il doit être décidé soit de déployer, soit d'itérer le processus en améliorant ce qui a été mal ou pas effectué.
Déployer
C'est la phase de livraison et de bilan de fin de projet. On établit les plans de contrôle et de maintenance et on rédige le rapport de fin de projet. Afin de déployer un modèle prédictif, on utilise le langage PMML - basé sur le XML - qui permet de décrire toutes les caractéristiques du modèle et de le déployer sur d'autres applications compatibles PMML.
D'autres méthodes
SEMMA
La méthodologie SEMMA (Sample then Explore, Modify, Model, Assess) inventée par le SAS Institute, se concentre sur les activités techniques du data mining. Bien qu'elle soit présentée par SAS comme seulement une organisation logique des outils de SAS Enterprise miner, SEMMA peut être utilisée pour organiser le processus de data mining indépendamment du logiciel utilisé.
Six Sigma (DMAIC)
Six Sigma (DMAIC est un acronyme caractérisant la méthode comme suit: Define, Mesure, Analyse, Improve, Control) est une méthodologie structurée, orientée données, dont le but est l'élimination des défauts, des redondances, et des problèmes de contrôle qualité de toutes sortes dans les domaines de la production, de la fourniture de service,du management, et d'autres activités métiers.
Conclusion
|
Le coeur du data mining est constitué par la modélisation: toute la préparation est effectuée en fonction du modèle que le statisticien envisage de produire, les tâches effectuées ensuite valident le modèle choisi, le complètent et le déploient. La tâche la plus lourde de conséquences dans la modélisation consiste à déterminer le ou les algorithmes qui produiront le modèle attendu. La question importante est donc celle des critères qui permettent de choisir cet algorithme.

















































