Exploration de données - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
L’exploration de données (terme recommandé en France par la DGLFLF, et au Canada par l'OQLF), aussi connue sous les noms fouille de données, data mining (forage de données) ou encore extraction de connaissances à partir de données (ECD en français, KDD en anglais), a pour objet l’extraction d'un savoir ou d'une connaissance à partir de grandes quantités de données, par des méthodes automatiques ou semi-automatiques. L'utilisation industrielle ou opérationnelle de ce savoir dans le monde professionnel permet de résoudre des problématiques très diverses, allant de la gestion de relation client à la maintenance préventive, en passant par la détection de fraudes ou encore l'optimisation de sites web.
Le data mining fait suite - dans l'escalade de l'exploitation des données de l'entreprise - à l'informatique décisionnelle. Celle-ci permet de constater un fait (e.g le chiffre d'affaire) et de l'expliquer (le chiffre d'affaire par produits), tandis que le data mining permet de classer les faits et de les prévoir dans une certaine mesure (quel sera le chiffre d'affaire dans un mois ?).
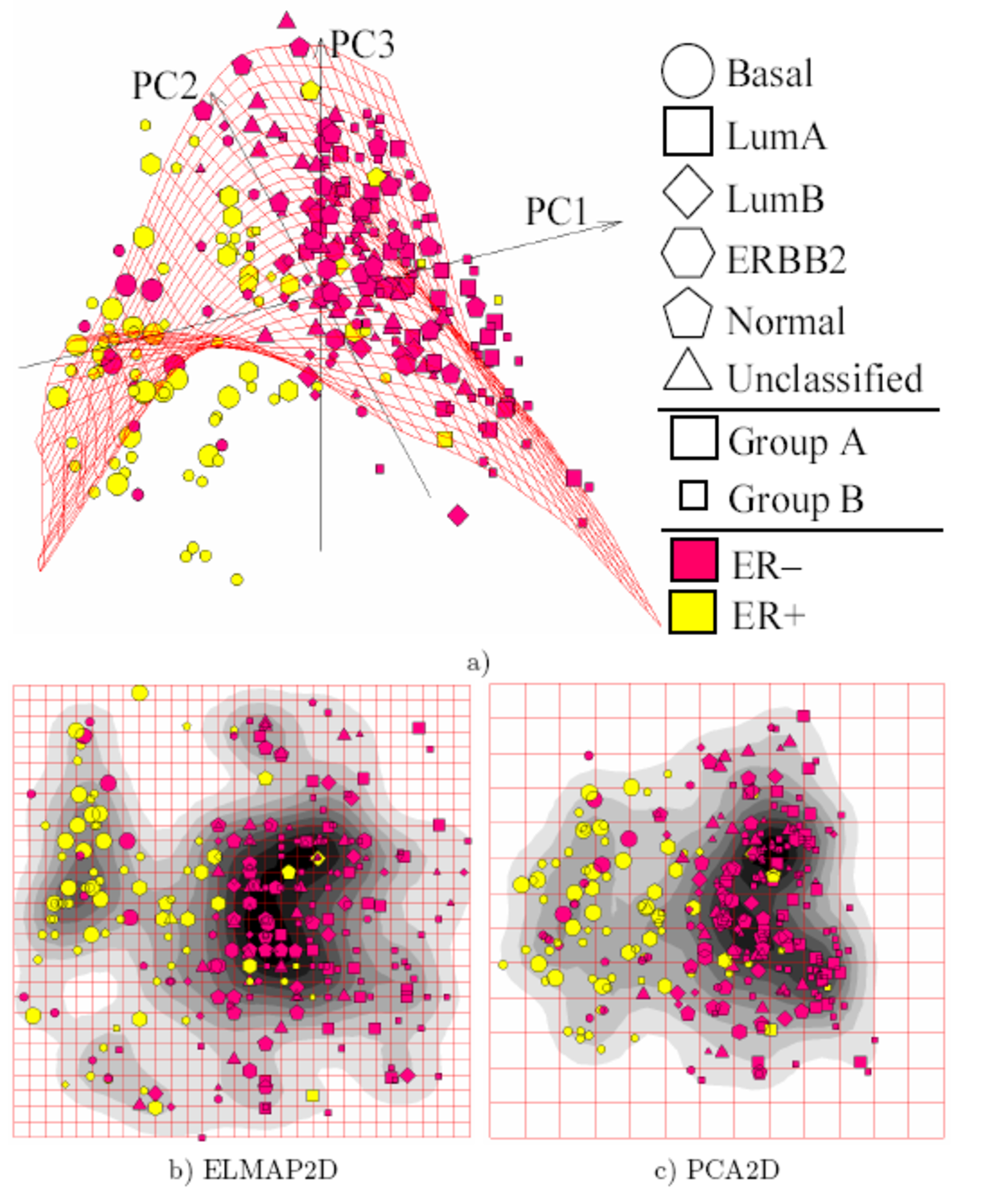
Histoire
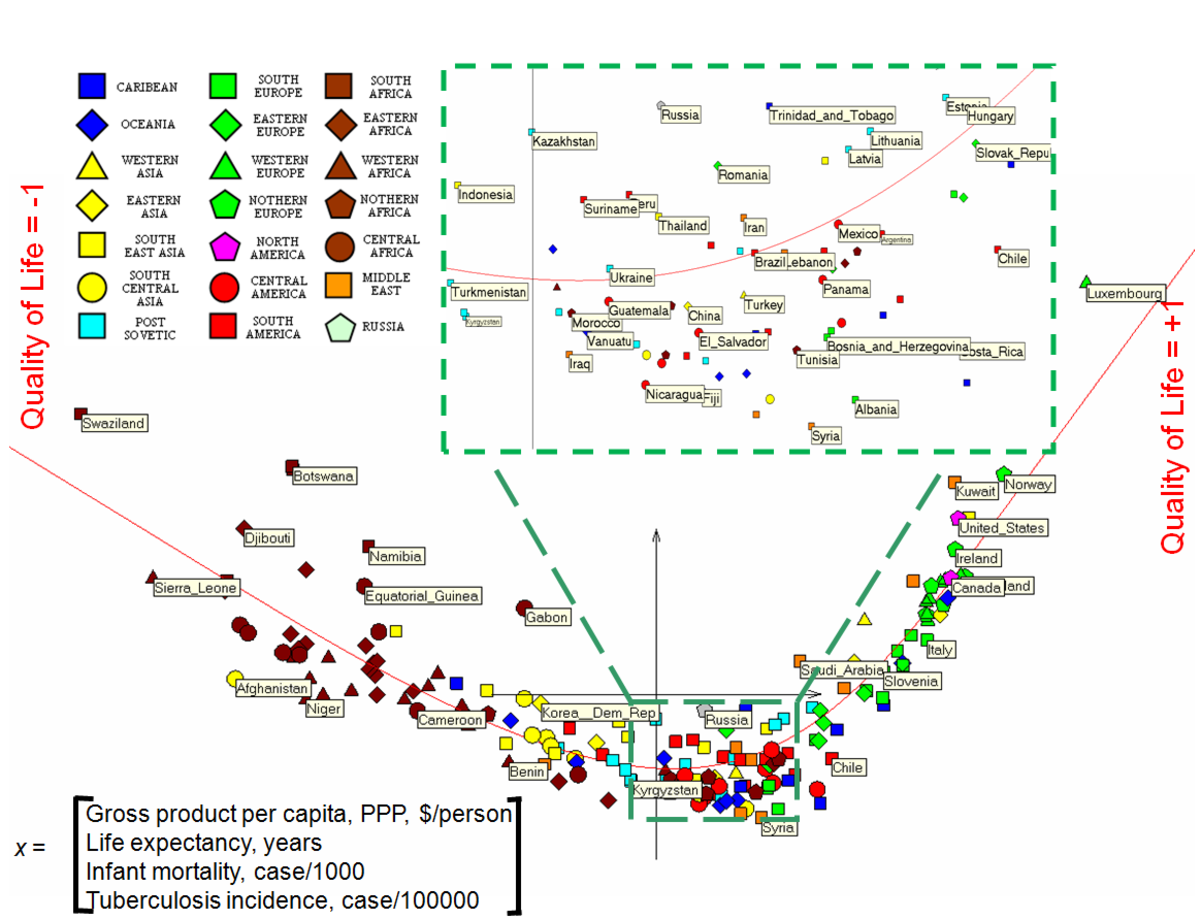
L'extraction de modèles à partir d'un grand nombre de données n'est pas un phénomène récent. Pour qu'il y ait extraction de modèle il faut qu'il y ait collecte de données. En Chine on prête à l'Empereur Tang, Yao, la volonté de recenser les récoltes en 2238 avant J.-C. ; en Egypte le Pharaon Amasis organise le recensement de sa population au cinquième siècle avant J.-C.. Ce n'est qu'au XVIIIe siècle qu'on commence à vouloir analyser les données pour en rechercher des caractéristiques communes. En 1763, Thomas Bayes montra qu'on peut déterminer, non seulement des probabilités à partir des observations issues d’une expérience, mais aussi les paramètres relatifs à ces probabilités. Présenté dans le cas particulier d'une loi binomiale ce résultat fut étendu indépendamment par Laplace, conduisant à une formulation générale du théorème de Bayes. Legendre publia en 1805 un essai sur la méthode des moindres carrés qui permet de comparer un ensemble de données à un modèle mathématique.
Dans les années 1920, Ronald Fisher mit au point l'analyse de la variance comme outil pour son projet d'inférence statistique médicale. Plus tard, dans les années 1950, l'apparition du calculateur et des techniques de calcul sur ordinateur tels que la segmentation, les réseaux de neurones et les algorithmes génétiques, dans les années 1960, les arbres de décisions, et dans les années 1980, les SVM, permirent aux chercheurs d'exploiter et de découvrir des modèles de plus en plus précis. En France, Jean-Paul Benzécri inventa l'analyse factorielle dans les années 1960.
Aujourd'hui, une entreprise comme Amazon.com se sert de tous ces outils pour proposer à ses clients d'autres achats qui seraient susceptibles de les intéresser.

















































