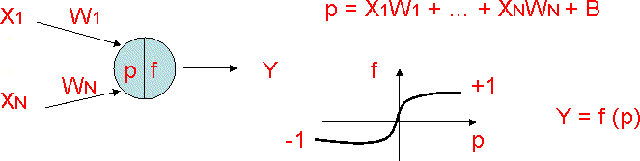L'auteur de ce dossier est Eric PARA, vous pouvez le contacter par mail à l'adresse [email protected]. Plus de détails sur le sujet abordé par ce dossier sont disponibles sur le site Internet de l'auteur: lien
Pour vous familiariser aux réseaux de neurones, je vous invite à lire notre premier dossier à ce sujet: lien
Introduction
Personne ne s'étonne, en voyant son voisin dans la rue, de le reconnaître instantanément. Et pourtant cela relève de l'impossible pour les ordinateurs actuels. De même que bons nombres de processus liés à la vision, la reconnaissance des formes en général pose de gros problèmes de mise en oeuvre et nombreuses sont les équipes à travers le monde à chercher des solutions à la fois rapides et fiables, les applications possibles étant très nombreuses et passionnantes (robotique, IA, domaine médical, sécurité, etc.).
En complément du précédent, ce dossier présente donc une des applications possibles aux réseaux de neurones. Nous allons donc voir comment détecter un visage humain dans une image puis identifier la personne par rapport à toutes celles déjà rencontrées. Ce qui parait ainsi simple pour un humain devient tout de suite extrêmement complexe pour un ordinateur, et aujourd'hui encore, aucune solution globale n'a été développée. De rares applications commencent cependant à fonctionner mais restent utilisables uniquement en environnement contrôlé (éclairage fixe devant un fond connu, conditions d'apprentissages identiques à celles des tests, etc.), et restent à la merci du bon vouloir de la personne (pas d'utilisation de fausses moustaches, lunettes, barbes, etc.).
De nombreuses techniques sont actuellement explorées pour l'identification de visages. On peut citer à titre d'exemples l'utilisation de critères morphologiques (distance entre les yeux, taille ou forme de la bouche, géométrie globale du visage, etc.), la détection de la couleur de la chair (par décomposition colorimétrique on peut isoler les zones de peau, l'origine ethnique n'influant que très peu sur la chrominance), ou encore la transformation en ondelettes. Celle que nous allons développer ici est la modélisation neuronale qui offre certains avantages par rapport aux précédentes sans pour autant régler tous les problèmes.
2 - Reconnaissance des formes et réseaux de neurones
Méthode des k-ppv
La méthode la plus simple de reconnaissance des formes est appelée k-ppv pour "k plus proches voisins". Elle consiste simplement à mesurer la distance euclidienne entre l'image à tester et toutes les images présentes dans la base d'apprentissage afin d'en déterminer les k plus faibles. Il suffit alors de déterminer à quelle classe appartient l'objet en question. L'avantage principal réside dans une programmation extrêmement rapide et un temps d'accès aux informations utiles immédiat (pas de nécessité d'apprentissage). Par contre, il faut disposer d'un bon échantillon d'images de l'objet à caractériser. Cette méthode limitée est donc essentiellement utilisée dans des environnements industriels contrôlés où un faible nombre d'images suffit à la discrimination. Dans le cas d'un environnement non contrôlé, il faudrait au contraire détenir à l'avance les images de l'objet sous différents angles, illuminations, zoom, etc. Le temps de calcul nécessaire au parcours de toutes les images de la base pour effectuer le calcul de distance devient alors beaucoup trop important, bien que des algorithmes de rapprochement et de parcours particuliers de la base permettent une accélération.
Un autre critère important est l'incrémentalité des données. En effet, un système de reconnaissance doit être dynamique et pouvoir évoluer dans le temps en fonction de l'expérience. Pour un visage, ceci est particulièrement vrai, le temps transformant petit à petit l'aspect physique, mais il faut aussi prendre en compte l'ajout éventuel de nouvelles personnes dans la base de référence. Dans le cas de la méthode des k-ppv, l'indexation d'une nouvelle image d'un visage, ou d'une nouvelle personne se fait donc très facilement puisque il suffit de l'ajouter à la base, cela ne nécessitant en outre aucun temps d'apprentissage ou de traitement particulier, ce qui explique son utilisation dans les cas simples.
Rappel sur le neurone artificiel
Les deux prochaines méthodes sont basées sur l'utilisation de réseaux de neurones. Un petit rappel sur le neurone artificiel s'impose donc:
Chaque neurone est relié à différentes entrées ( X ). Celles-ci sont soit les variables d'entrées du réseau, soit les sorties des couches précédentes. Chacune de ces entrées est pondérée par un poids ( W ). Un poids total ( p ) est ainsi calculé après rajout du biais ( B ) propre à chaque neurone. Ce poids normalisé entre -1 et 1 indique le degré d'activation du neurone. Une fonction sigmoïde ( f ) est alors utilisée pour la propagation de l'information et donne une sortie ( Y ) toujours normalisée entre -1 et 1. Toutes les informations sont alors stockées dans la valeur des poids et un algorithme d'apprentissage par rétropropagation, que nous ne développerons pas ici, sur de nombreux exemples est nécessaire à l'optimisation d'une solution.
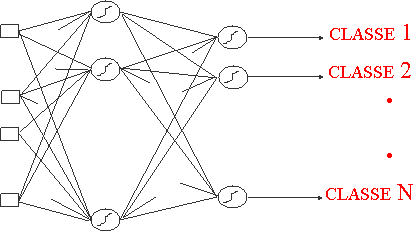
Réseau de neurones discriminant
Une méthode classique de classification neuronale repose sur l'utilisation d'un réseau discriminant qui permet de prendre en compte toutes les informations de chaque classe afin de mieux pouvoir les séparer. Ce réseau est un perceptron multi-couches à architecture figée, tous les neurones d'une couche étant reliés à chacun de la couche précédente et possédant une couche intermédiaire entre l'entrée et la sortie dite de "cachée". La méthode du réseau discriminant repose donc sur l'utilisation d'un unique réseau de neurones donnant en sortie la classe d'appartenance (dans notre cas le nom de la personne) d'une image inconnue en entrée. Il est composé d'une couche d'entrée, d'une couche cachée et de N sorties pour autant de personnes à discriminer:
Il y a donc autant de cellules d'entrées que de pixels composant les images. Ceci impose que toutes les images soient de tailles identiques. Afin de réduire la complexité du réseau, une taille de 15x15 peut par exemple être choisie, ce qui porte à 225 le nombre d'entrées. La couche cachée est composée d'un nombre plus ou moins important de neurones (entre 10 et 200) dont dépendra le temps nécessaire à l'apprentissage et le résultat.
Le principal avantage par rapport au calcul des distances euclidiennes réside dans le temps de calcul nécessaire à l'identification. En effet, celui-ci n'est lié qu'à la complexité du réseau de neurones. Mais même avec de nombreuses cellules sur la couche cachée, la propagation de l'entrée vers la sortie se fait de manière quasi-instantanée ( en ms ). La taille des données stockées est également fortement réduite, puisque le réseau ( quelques ko ) remplace tout besoin d'images de références.
Par contre, cette méthode nécessite un très long apprentissage qui dépend du nombre de neurones sur la couche cachée et surtout du nombre de classes en sortie. Avec 33 personnes à discriminer et 120 neurones sur la couche cachée, il faut compter un minimum de 48 heures de calculs avec un P4 (calculs réalisés sous le système Matlab, ce qui permet d'espérer un gain conséquent en langage C) !! On imagine alors la difficulté pour ajouter une nouvelle personne à la base ou tout simplement une nouvelle image d'un visage existant (exemple de l'apparition soudaine et inexpliquée d'une barbe de trois jours par exemple !). Dans ce cas, un réapprentissage total du réseau est nécessaire. Un autre type de réseau a donc été utilisé.
Réseaux de neurones de modélisation
La troisième méthode est ainsi basée sur une série de réseaux de neurones de type diabolo. Plutôt que de chercher à discriminer chaque classe, une modélisation de chaque individu est ici réalisée. La particularité de ce réseau réside dans un nombre de sorties identique au nombre d'entrées, le but étant alors d'obtenir une sortie la plus proche possible de l'entrée dans le cas d'une image appartenant à la bonne classe. Chaque personne est donc stockée dans un réseau propre (entre 50 et 200 Ko). Concrètement, en phase d'apprentissage, toutes les images décrivant un individu vont ainsi permettre l'apprentissage d'un unique réseau décrivant la personne, l'image de sortie devant être identique à l'entrée et ce pour chaque image. Lors du test, chaque nouvelle image est propagée dans les différents réseaux diabolos puis une mesure de distance entre le vecteur d'entrée et de sortie est réalisée. Puisqu'il s'agit d'un réseau modélisateur, plus cette distance sera faible, meilleur sera la probabilité d'appartenance à la classe testée. La mesure la plus faible est alors retenue pour le choix de la personne.
Pour imager la technique, on peut prendre l'exemple abstrait de deux classes, celle d'un chien et une autre d'un chat. Deux réseaux différents sont alors appris, l'un modélisant un chien à partir d'images de chien et l'autre avec un chat. Si on présente maintenant une image de chien au premier réseau, une image de sortie de chien sera présente alors qu'une image mélange entre chien et chat sera donnée par le second réseau. Le premier avantage de la méthode devient alors évident. Si l'on présente aux réseaux connus une image d'un objet inconnu, aucune réponse satisfaisante ne sera donnée, et une nouvelle classe pourra éventuellement être apprise indépendamment de l'architecture déjà existante. Dans le cas du réseau discriminant unique, une telle souplesse était impossible.
Par contre, le temps de calcul nécessaire à l'identification est légèrement plus élevé qu'avec la méthode précédente (propagation dans plusieurs réseaux avec calculs de distance entre sorties et entrées) mais reste tout à fait faible en comparaison de la méthode de calcul des distances euclidiennes à chaque image. Le grand avantage apporté par l'utilisation de réseaux modélisateurs réside dans la simplicité et la rapidité d'incrémentalité. Seul l'apprentissage du réseau de la nouvelle personne est ainsi nécessaire pour agrandir la base ou en modifier la modélisation d'une personne. De plus, les réseaux étant indépendants les uns des autres, un apprentissage en parallèle devient possible, augmentant la rapidité des tests de configuration, surtout si l'on ajoute à cela une complexité nécessaire réduite de l'architecture. Enfin, les résultats d'identification sont meilleurs avec cette méthode qu'avec la précédente et c'est cette méthode qui a été choisie pour la suite de l'application.
3 - Identification de personnes
Nous allons maintenant voir la méthode de modélisation neuronale appliquée à l'identification de personnes, qui ne doit pas être confondue avec la détection d'un visage dans une image que nous détaillerons par la suite. Ici, le but étant "simplement" de déterminer le nom de la personne à partir d'une image de visage. Pour les besoins de l'expérience, une base de 33 personnes à été choisie, chacune d'elles ayant été photographiée dans 38 postures différentes (face jusqu'à profil, rotation de la tête, regard vers le bas, le haut, sourire, grimace, etc.). Un détourage manuel a ensuite été effectué pour ne conserver que le visage. Se pose alors une première question: doit on faire un détourage serré ne conservant que le visage à proprement parlé, ou doit on également conserver la chevelure et les oreilles ? L'avantage du premier cas et de permettre la reconnaissance d'une personne même avec une coupe de cheveux différente. Or on en a tous fait l'expérience, un passage chez le coiffeur quelque peu original, voire un précédent datant d'un peu, et on a plus de mal à se faire reconnaître ! La chevelure constitue donc une source importante d'informations discriminantes et la prise en compte de celle-ci améliore logiquement les résultats d'identification.
La première étape consiste donc à apprendre à modéliser les différentes personnes. L'apprentissage est depuis de nombreuses années au cœur des recherches en intelligence artificielle. L'idée de résoudre un problème uniquement à partir d'exemples ou d'actions expérimentées à partir d'un petit programme informatique est particulièrement séduisante. L'apprentissage utilisé dans notre application est dit de supervisé car il se fait à partir d'exemples dont la solution est connue (ici, le nom de la personne). Il est à différencier de l'apprentissage non supervisé où le système choisit lui même si la décision choisie est la bonne ou pas en fonction de son état interne (par exemple un robot qui s'arrête sur sa plate forme de rechargement verra sa durée de vie augmentée) ou d'une récompense (cas du dressage d'un fauve où l'utilisation de nourriture permet tous les exploits !).
De manière plus formelle, l'apprentissage à pour but l'extraction des informations pertinentes à l'identification. Et c'est justement le rôle de la couche cachée des réseaux diabolos utilisés. Pourquoi "diabolo" ? Tout simplement à cause de leurs architectures: N pixels en entrée, N en sortie et entre les deux, un nombre de cellules plus réduit servant à compresser l'information utile. Cependant, l'utilisation d'exemples pour apprendre apporte le risque de ne pouvoir résoudre que des situations déjà rencontrées. Or il est nullement nécessaire d'avoir déjà vu un mouton noir pour en reconnaître un le cas échéant. La généralisation de l'apprentissage est donc une étape primordiale. Dans le cas de l'identification de visage, l'utilisation de plusieurs postures de référence reste insuffisante. On augmente alors les exemples en procédant à des transformations géométriques sur les images. Diverses translations et rotations sont alors effectuées et pour minimiser l'influence de la direction de l'éclairage, des symétries sont également utilisées. On obtient de cette manière non plus 38 exemples (postures différentes) par personnes, mais 38x37, ce qui permet au réseau modélisateur de mieux extraire les informations pertinentes.
Nous donnent:
Une base de données de 46 398 images
Le fait de disposer d'autant d'images couleurs de grandes tailles ne permet pas d'envisager un apprentissage dans des délais raisonnables. De plus, la couleur comme la précision n'apporte rien à l'identification (il suffit de feuilleter certains magazines télé où de petites illustrations en 4 niveaux de gris permettent pourtant de reconnaître son actrice préférée !). Un rééchantillonnage des images est donc fait et une dimension de 15 par 15 semble suffire. Cela peut paraître trop peu (et l'est sans doute), mais il faut savoir que le nombre d'entrées du réseau est proportionnel au carré du côté et que le nombre de connections entrées-sorties est alors plus important. De plus, un nombre plus élevé de cellules cachées devient nécessaires pour la compression.
Acteur connu en résolution 15x15 bilinéarisée
L'apprentissage à proprement parler peut ainsi commencer. L'algorithme consiste alors à faire converger le réseau de modélisation de manière à ce que la sortie soit la reproduction la plus fidèle possible de l'entrée pour chaque exemple. La méthode commune repose sur un apprentissage par itérations où l'erreur est utilisée pour améliorer la convergence. On parle alors d'algorithme de rétropropagation. D'autres méthodes sont cependant envisageables tel que l'utilisation d'algorithmes génétiques par exemples. Pour pouvoir tester les résultats, la base initiale est découpée en 3 parties. La première, la plus importante, sert à l'apprentissage. La seconde permet de tester le réseau en cours d'apprentissage pour éviter un phénomène de sur-apprentissage qui spécialiserait le réseau uniquement sur les exemples connus sans généraliser. La dernière partie est uniquement utilisée pour le test final afin de disposer d'exemples nouveaux et indépendant de l'apprentissage. Les résultats obtenus au cours d'un stage réalisé au LISIF de l'universitéParis VI ont été inférieurs à 6% d'erreur pour une base de 33 personnes, ce qui montre la viabilité de la méthode.
4 - Détection de visages dans une image
Nous venons de voir comment identifier un visage à partir de son imagette mais qu'en est il de la détection du visage en tant que tel dans une image globale ? Cette fois ci, le but va être de reconnaître non plus un visage en particulier parmi d'autres mais de trouver un ou plusieurs visages dans une image. Ce qui parait une fois de plus comme évident pour nous devient extrêmement complexe d'un point de vuealgorithmique. Pensez qu'un visage peut avoir des orientations, mais également des dimensions très différentes, sans parler une fois de plus des conditions d'éclairage ni de sa position dans l'image.
Comme précédemment, l'idée la plus simple, celle des k-ppv, serait de parcourir l'image avec un cadre puis de comparer chaque imagette extraite avec une série de visages types et de définir un visage comme étant tout résultat dont la distance à l'une des images de la base soit suffisamment faible. Mais en considérant des tailles, des orientations, rotations et des éclairage différents il faudrait pouvoir comparer chaque imagette extraite à des centaines de références !! Si l'on rajoute les expressions faciales (sourires, grimaces, etc.), on ne s'en sort plus. Partant de ce constat, d'autres méthodes cherchent à ne trouver que des éléments stables et relativement descriptifs. Les yeux paraissent ainsi suffisamment communs et discriminant de par leurs formes ou leur différence de contraste avec les pixels voisins. On notera ainsi l'utilisation bien connue de templates, sortes de modèles applicables à la recherche des ces éléments dans l'image, soit brute soit transformée (image contour, etc.).
L'avantage du réseau de neurones de modélisation réside dans la compression d'une multitude d'images globales de visages en un réseau unique. Il devient alors possible de rassembler une multitude de cas et ne faire qu'un unique test sur chaque imagette. En insérant des zooms différents lors de l'apprentissage, il ne devient alors plus nécessaire de tester chaque dimension potentielle. Le parcours d'extraction en multi-dimension reste cependant vrai, rien n'interdisant la présence d'un visage occupant toute l'image ou uniquement un dixième dans le coin inférieur droit ... De même qu'avec l'identification, le test s'effectue donc sur une différence entre l'entrée et la sortie du réseau dans laquelle l'imagette extraite s'est propagée. Dans le cas d'un visage, l'image de sortie sera proche de l'image d'entrée alors que dans le cas contraire, un mélange entre entrée et sotie sera obtenu.
Image de recherche - Image de diffusion - Image résultat
L'image de diffusion correspond à l'affichage de l'erreur pour chaque position de la recherche. Plus le point est sombre, moins l'erreur est importante. On constate donc bien une "tache de visage potentiel" au bon endroit. L'image résultat est alors la superposition de ce que "voit" notre réseau à l'endroit le plus probable. Mais la détection d'un visage ou d'une forme en général pose de nombreuses autres questions. Comment arrive t-on à reconnaître immédiatement une voiture à moitié cachée derrière un arbre ? Le cas de l'occultation pose ainsi de réelles difficultés pour la reconnaissance des formes, tracking d'objets et autres applications de vision. Sûrement y a t-il une multitude de modélisation pour un même objet et non une unique représentation globale. Pour le visage, la présence d'un œil ou d'une bouche suffit alors à détecter la présence d'une personne et d'en reconstituer mentalement une représentation au moins dans un but de positionnement.
Image partiellement occultée - Image de diffusion - Image résultat
Dans le cas de ce "trou" sur le visage, l'image de diffusion est moins discriminante et la position réelle ressort moins qu'auparavant. En outre le visage donné par la sortie du réseau est légèrement différent du précédent. Cependant, en regardant le détail de la différence entre l'entrée et cette sortie, on retrouve la zone dégradée, le reste de l'image ayant une excellente correspondance. Il faut par contre éviter de considérer toute image partiellement masquée comme juste au risque de voir des visages partout ! Il est ainsi fréquent que le cerveau humain soit pris à défaut et chacun a ainsi déjà vu des visages dans les nuages...
Image différence sans occultation - Image différence avec occultation
Malgré ses avantages, la méthode du réseau modélisateur seule ne permet pas actuellement une détection en temps réel d'un visage dans une image. Il est cependant inutile de tester toutes les positions de l'image et un couplage avec d'autres techniques non neuronales, par exemple la restriction à la couleur de la chair, permet l'accélération des calculs dans un premier temps avant d'affiner la détection avec le réseau. Dans le cas d'une application de tracking, un test périodique sur l'objet suivi peut également suffire à limiter les erreurs. Mais rien n'empêche non plus de concevoir une puce neuronale directement reliée en parallèle au capteur CCD et possédant autant de réseaux que de positions et tailles possible ! Cela peut alors paraître irréalisable, mais il faut savoir qu'un réseau de neurones n'est constitué que de briques élémentaires (principalement l'addition et la multiplication) et qu'avec les niveaux d'intégration actuels, cette puce serait bien plus petite que le capteur optique lui même.
5 - Conclusion
Nous venons donc de voir une application possible aux réseaux de neurones. Actuellement cette technique se développe dans l'industrie sortant du cadre de la recherche pure. Dans certains cas précis, les réseaux de neurones apportent en effet une bien meilleure solution que d'anciennes techniques. De nombreuses applications sont ainsi concernées, notamment en vision (reconnaissance de l'écriture manuscrite, lecture de chèque, de plaques de d'immatriculations) et en automatisme (commande non linéaire de mouvements pour les robots, modélisation de systèmes complexes, etc.). Mais ce qui caractérise avant tout ces réseaux, c'est leur comportement de boite noire. A l'image d'un chapeau de magicien, les exemples nécessaires sont récoltés en nombre, puis l'apprentissage fourni au bout d'un certain temps un système avec entrées sorties dont le comportement interne n'est pas connu avec exactitude. L'organisation des liaisons et des poids d'un réseau est alors difficilement explicable concrètement et on ne peut en comprendre toutes les subtilités.
Ces dix dernières années ont étés riches en découvertes. On a ainsi énormément diversifié les architectures des réseaux et les méthodes d'apprentissage. Aujourd'hui, de nombreuses recherches portent par exemple sur les cellules de lieu (localisation de robots mobiles et création de cartes dynamiques) ou sur la compréhension des liaisons neuronales animales (hypothalamus du rats ou du criquet) pour en reproduire les comportements dans un cerveau artificiel. D'autres chercheurs tentent quant à eux de remodéliser le neurone artificiel en y introduisant des fonctions plus complexes permettant une meilleure élasticité pour se rapprocher de ce qui existe chez les animaux. Il semble en effet que toutes les clefs n'ont pas encore été trouvées. Un simple insecte tel que l'abeille possédant quelques 960 000 neurones est en effet capable de généralisations étonnantes. En lui présentant des objets très variés, on est ainsi capable de lui faire apprendre une classification suivant des critères abstraits tels que la symétrie. Or, il faut bien admettre qu'aujourd'hui, aucun réseau n'est capable, à partir de quelques exemples, d'aboutir à l'émergence de la notion de symétrie.
La détection et la reconnaissance des visages montre bien les difficultés rencontrées dans le domaine de la reconnaissance des formes en vision. L'utilisation des réseaux de neurones va sûrement permettre dans les années à venir de solutionner de nombreux problèmes. Mais un travail de fond est nécessaire et de nombreuses questions demandent à être élucidées. Que dire en effet de la généralisation aux visages stylisés (dessin, tableau, traits abstraits) où seuls quelques coups de crayon arrivent à nous faire voir un visage humain ?! Il reste donc de nombreuses années de recherches passionnantes pour comprendre et reproduire les capacités du cerveau animal puis humain...