Régression linéaire multiple - Définition
La liste des auteurs de cet article est disponible ici.
Modèle théorique
La régression linéaire multiple est une généralisation, à p variables explicatives, de la régression linéaire simple.
Nous sommes toujours dans le cadre de la régression mathématique : étant donné un échantillon



où


Exemple
Nous relevons 20 fois les paramètres suivants : la demande totale en électricité (ce sera notre yi, i étant compris entre 1 et 20) la température extérieure (ce sera notre xi1) l'heure à laquelle les données sont prises (ce sera notre xi2)
Faire une régression linéaire revient à déterminer les ao, a1 et a2 et

Estimation
Lorsque nous disposons de n observations



La problématique reste la même que pour la régression simple :
- estimer les paramètres ai en exploitant les observations ;
- évaluer la précision de ces estimateurs ;
- mesurer le pouvoir explicatif du modèle ;
- évaluer l'influence des variables dans le modèle :
- globalement (les p variables en bloc) et,
- individuellement (chaque variable) ;
- évaluer la qualité du modèle lors de la prédiction (intervalle de prédiction) ;
- détecter les observations qui peuvent influencer exagérément les résultats (points atypiques).
Notation matricielle
Nous pouvons adopter une écriture condensée qui rend la lecture et la manipulation de l'ensemble plus facile. Les équations suivantes

peuvent être résumées avec la notation matricielle

Soit de manière compacte:

avec
- y est de dimension (n, 1)
- X est de dimension (n, p + 1)
- a est de dimension (p+1, 1)
- ε est de dimension (n, 1)
- la première colonne sert à indiquer que nous procédons à une régression avec constante.
Hypothèses
Comme en régression simple, les hypothèses permettent de déterminer : les propriétés des estimateurs (biais, convergence) ; et leurs lois de distributions (pour les estimations par intervalle et les tests d'hypothèses).
Il existe principalement deux catégories d'hypothèses :
- Hypothèses stochastiques
-
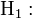
-
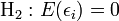
-
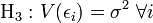
-
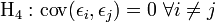
-
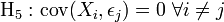
-
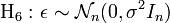








- Hypothèses structurelles
-
-
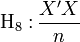
 Le nombre d'observations est supérieur au nombre de variables + 1 (la constante). S'il y avait égalité, le nombre d'équations serait égal au nombre d'inconnues aj, la droite de régression passerait par tous les points, nous serions face à un problème d'interpolation linéaire (voir Interpolation numérique).
Le nombre d'observations est supérieur au nombre de variables + 1 (la constante). S'il y avait égalité, le nombre d'équations serait égal au nombre d'inconnues aj, la droite de régression passerait par tous les points, nous serions face à un problème d'interpolation linéaire (voir Interpolation numérique).


- Écriture matricielle de l'hypothèse H6

Sous l'hypothèse d'homoscedasticité et d'absence d'auto-corrélation, la matrice de variance-covariance du vecteur des erreurs peut s'écrire:

Régresseurs stochastiques
Dans certains cas, l'hypothèse (H1) est intenable : les régresseurs X sont supposés aléatoires. Mais dans ce cas, on suppose que X est aléatoire mais est indépendant de l'aléa


De même, il faudrait changer en conséquence les hypothèses (H3), (H4) et aussi (H5).

















































