Distance de Hamming - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
La distance de Hamming, définie par Richard Hamming, est utilisée en informatique, en traitement du signal et dans les télécommunications. Elle joue un rôle important en théorie algébrique des codes correcteurs. Elle permet de quantifier la différence entre deux séquences de symboles.
La distance de Hamming est une distance au sens mathématique du terme. À deux suites de symboles de même longueur, elle associe le nombre de positions où les deux suites diffèrent.
Le poids de Hamming correspond au nombre d'éléments différents de zéro dans une chaîne d'éléments d'un corps fini.
Intérêt du concept
Histoire et domaine d'applications
La distance de Hamming doit son nom à Richard Hamming . Elle est décrite dans un article fondateur pour la théorie des codes. Elle est utilisée en télécommunication pour compter le nombre de bits altérés dans la transmission d'un message d'une longueur donnée. Le poids de Hamming correspond au nombre de bits différents de zéro, il est utilisé dans plusieurs disciplines comme la théorie de l'information, la théorie des codes et la cryptographie. Néanmoins, pour comparer des séquences de longueurs variables, ou des chaines de caractères pouvant subir non seulement des substitutions, mais aussi des insertions ou des effacements, des métriques plus sophistiquées comme la distance de Levenshtein sont plus adaptées.
Motivation
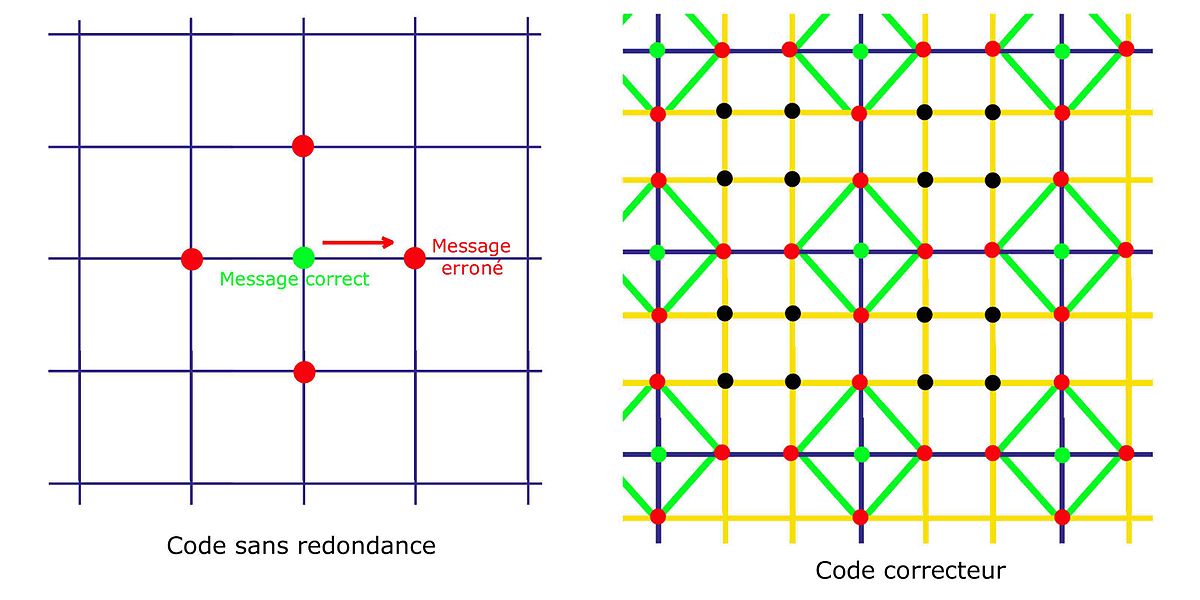
Les codes correcteurs ont leurs sources dans un problème de la transmission de données. Parfois, une transmission de données se fait en utilisant une voie de communication non entièrement fiable. L'objectif d'un code correcteur est l'apport d'une redondance de l'information de telle manière à ce que l'erreur puisse être détectée voire corrigée.
Un message est un élément d'un ensemble E constitué de suites finies de lettres choisies dans un alphabet A. L'apport de la redondance est le résultat d'une application injective φ de E dans un ensemble F constitué aussi de suite finies de lettres d'un alphabet A'. Les suites de l'ensemble F sont choisies a priori plus longues que celle de E. L'ensemble φ(E) est appelé code et un élément de cet ensemble φ(m) mot du code. L'intérêt de transmettre φ(m) à la place de m est illustré par la figure à droite :
Le cas d'un code sans redondance est illustré à gauche sur la figure. F est alors égal à E et φ est l'identité. Si un message en vert subit, lors de sa transmission, une altération, un nouveau message en rouge est transmis. Aucune information ne laisse supposer qu'une erreur a été commise.
Pour pallier cet état, l'objectif est d'entourer les mots du code, correspondant, sur la figure de droite aux points verts, par des messages connus pour contenir des erreurs. Ces redondances sont illustrées par les intersections du quadrillage orange. Si une unique erreur se produit, alors le message transmis correspond à un point rouge. Si la redondance a été habilement construite, il n'existe qu'un point vert proche du point rouge reçu, l'erreur est corrigible.
La distance de Hamming correspond sur la figure au plus petit nombre de segments du quadrillage à traverser pour joindre deux points.
Propriété
Distance
La distance de Hamming est une distance au sens mathématique du terme :

| (symétrie) |

| (séparation) |

| (inégalité triangulaire) |
La troisième propriété se démontre par une récurrence sur n.
Capacité de correction et distance minimale
La distance minimale δ est le minimum de distance entre deux mots du code. Elle permet de déterminer le nombre maximal d'erreurs t corrigibles de manière certaine. La valeur de t est en effet celle du plus grand entier strictement inférieur à δ/2.
Si M désigne le nombre de mot du code, q le nombre de lettres de l'alphabet A de F et Vt le cardinal d'une boule fermée de rayon t, alors la majoration suivante est vérifiée:

Cette majoration porte le nom de Borne de Hamming.
Dans le cas d'un code linéaire, et si k désigne la longueur des mots du codes, il existe une autre majoration, dite du borne du singleton :

















































