Théorie de la complexité des algorithmes - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
La théorie de la complexité des algorithmes étudie formellement la difficulté intrinsèque des problèmes algorithmiques.
Histoire
Dans les années 1960 et au début des années 1970, alors qu'on en était à découvrir des algorithmes fondamentaux (tris tels que quicksort, arbres couvrants tels que les algorithmes de Kruskal ou de Prim), on ne mesurait pas leur efficacité. On se contentait de dire : « cet algorithme (de tri) se déroule en 6 secondes avec un tableau de 50 000 entiers choisis au hasard en entrée, sur un ordinateur IBM 360/91. Le langage de programmation PL/I a été utilisé avec les optimisations standards. » (cet exemple est imaginaire)
Une telle démarche rendait difficile la comparaison des algorithmes entre eux. La mesure publiée était dépendante du processeur utilisé, des temps d'accès à la mémoire vive et de masse, du langage de programmation et du compilateur utilisé, etc.
Une approche indépendante des facteurs matériels était nécessaire pour évaluer l'efficacité des algorithmes. Donald Knuth fut un des premiers à l'appliquer systématiquement dès les premiers volumes de sa série The Art of Computer Programming. Il complétait cette analyse de considérations propres à la théorie de l'information : celle-ci par exemple, combinée à la formule de Stirling, montre qu'il n'est pas possible d'effectuer un tri général (c'est-à-dire uniquement par comparaisons) de N éléments en un temps croissant moins rapidement avec N que N ln N sur une machine algorithmique (à la différence peut-être d'un ordinateur quantique).
Signalons également deux autres directions alternatives : la complexité en moyenne des algorithmes, dont le calcul passe souvent par des techniques sophistiquées d'analyse mathématique, et la complexité amortie des structures de données, qui consiste à déterminer le coût de suites d'opérations.
Classes de complexité
Dans ce qui suit nous allons définir quelques classes de complexité parmi les plus étudiées en une liste qui va de la complexité la plus basse à la complexité la plus haute. Il faut cependant avoir à l'esprit que ces classes ne sont pas totalement ordonnées.
Commençons par la classe constituée des problèmes les plus simples, à savoir ceux dont la réponse peut être donnée en temps constant. Par exemple, la question de savoir si un nombre entier est positif peut être résolue sans vraiment calculer, donc en un temps indépendant de la taille du nombre entier, c'est la plus basse des classes de problèmes.
La classe des problèmes linéaires est celle qui contient les problèmes qui peuvent être décidés en un temps qui est une fonction linéaire de la taille de la donnée. Il s'agit des problèmes qui sont en O(n).
Souvent au lieu de dire « un problème est dans une certaine classe C » on dit plus simplement « le problème est dans C ».
Classes L et NL
Un problème de décision qui peut être résolu par un algorithme déterministe en espace logarithmique par rapport à la taille de l'instance est dans L. Avec les notations introduites plus haut, L = SPACE(log(n)). La classe NL s'apparente à la classe L mais sur une machine non déterministe (NL = NSPACE(log(n)). Par exemple savoir si un élément appartient à un tableau trié peut se faire en espace logarithmique.
Classe P
Un problème de décision est dans P s'il peut être décidé sur une machine déterministe en temps polynomial par rapport à la taille de la donnée. On qualifie alors le problème de polynomial, c'est un problème de complexité O(nk) pour un certain k.
Un exemple de problème polynomial est celui de la connexité dans un graphe. Étant donné un graphe à s sommets (on considère que la taille de la donnée, donc du graphe est son nombre de sommets), il s'agit de savoir si toutes les paires de sommets sont reliées par un chemin. Un algorithme de parcours en profondeur construit un arbre couvrant du graphe à partir d'un sommet. Si cet arbre contient tous les sommets du graphe, alors le graphe est connexe. Le temps nécessaire pour construire cet arbre est au plus c.s² (où c est une constante et s le nombre de sommets du graphe), donc le problème est dans la classe P.
On admet, en général, que les problèmes dans P sont ceux qui sont facilement solubles.
Classe NP et classe Co-NP (complémentaire de NP)
La classe NP des problèmes Non-déterministes Polynomiaux réunit les problèmes de décision qui peuvent être décidés sur une machine non déterministe en temps polynomial. De façon équivalente, c'est la classe des problèmes qui admettent un algorithme polynomial capable de tester la validité d'une solution du problème, on dit aussi capable de construire un certificat. Intuitivement, les problèmes dans NP sont les problèmes qui peuvent être résolus en énumérant l'ensemble des solutions possibles et en les testant à l'aide d'un algorithme polynomial.
Par exemple, la recherche de cycle hamiltonien dans un graphe peut se faire à l'aide de deux algorithmes :
- le premier engendre l'ensemble des cycles (en temps exponentiel, classe EXPTIME, voir ci-dessous) ;
- le second teste les solutions (en temps polynomial).
Ce problème est donc de la classe NP.
La classe duale de la classe NP, quand la réponse est non, est appelée Co-NP.
Classe PSPACE
La classe PSPACE est celle des problèmes décidables par une machine déterministe en espace polynomial par rapport à la taille de sa donnée. On peut aussi définir la classe NSPACE ou NPSPACE des problèmes décidables par une machine non déterministe en espace polynomial par rapport à la taille de sa donnée. Par le théorème de Savitch, on a PSPACE = NPSPACE, c'est pourquoi on ne rencontre guère les notations NSPACE ni NPSPACE.
Classe EXPTIME
La classe EXPTIME rassemble les problèmes décidables par un algorithme déterministe en temps exponentiel par rapport à la taille de son instance.
Classe NC (Nick's Class)
La classe NC est la classe des problèmes qui peuvent être résolus en temps poly-logarithmique (c'est-à-dire résolus plus rapidement qu'il ne faut de temps pour lire séquentiellement leurs entrées) sur une machine parallèle ayant un nombre polynomial (c'est-à-dire raisonnable) de processeurs.
Intuitivement, un problème est dans NC s'il existe un algorithme pour le résoudre qui peut être parallélisé et qui gagne à l'être. C'est-à-dire, si la version parallèle de l'algorithme (s'exécutant sur plusieurs processeurs) est significativement plus efficace que la version séquentielle.
Par définition, NC est un sous ensemble de la classe P (NC

Mais on ne sait pas si P
Inclusions des classes
On a les inclusions :
- P
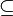
- NP

En effet, un problème polynomial peut se résoudre en engendrant une solution et en la testant à l'aide d'un algorithme polynomial. Tout problème dans P est ainsi dans NP.

















































