Analyse factorielle des correspondances - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
L'analyse factorielle des correspondances, en abrégée AFC, est une méthode statistique d'analyse des données mise au point par Jean-Paul Benzecri à l'Université Pierre-et-Marie-Curie à Paris (ISUP et Laboratoire de statistique multidimensionnelle)
Introduction
Dit grossièrement, une méthode AFC admet en entrée un "tableau croisé dynamique", et produit en sortie une ou plusieurs cartes ou images de répartition des valeurs et des variables. Exemple : La participation croisée boursière; si 6 investisseurs répartissent leurs portefeuilles entre 10 entreprises, on obtient par AFC une carte comprenant 16 points, dont 6 représentent chacun des investisseurs et les 10 autres représentent chacune des 10 entreprises. l'analyse apporte en fait l'information de distance entre les points permettant d'interpréter indirectement les pourcentages de participation au capital des entreprises.
La technique de l'AFC est essentiellement utilisée pour de grands tableaux de données toutes comparables entre elles (si possible exprimées toutes dans la même unité, comme une monnaie, une dimension, une fréquence ou toute autre grandeur mesurable). Elle peut en particulier permettre d'étudier des tableaux de contingence (ou tableau croisé de co-occurrence). De manière générale, les méthodes factorielles permettent l'analyse d'un tableau "agrégé" de mesures, correspondant aux requêtes du type "select count(*) from .. group by (tuple_dimensions)" en langage SQL ou aux tableaux croisés dynamiques sous Excel, tandis que les méthodes d'exploration de données travaillent directement sur les mesures récoltées pour chaque individu. Ces méthodes-là sont donc particulièrement recommandées pour les analyses de rapports d'études.
L'AFC sert à déterminer et à hiérarchiser toutes les dépendances entre les lignes et les colonnes du tableau.
Exemple d'application
Par exemple, on a demandé à un ensemble d'électeurs leur département et leur vote à l’élection présidentielle. Il est commode de regrouper ces données dans un tableau de contingence. Supposons qu'il y a I candidats et J départements :

- ni,j représente le nombre de personnes ayant voté pour le candidat i dans le département j.
Fréquemment, on utilise la fréquence remplaçant le nombre de personnes.
-
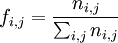
-
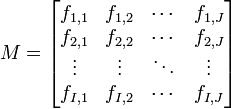


On note
-
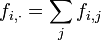

-
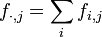

respectivement les profils-lignes et les profils-colonnes.
Un tel tableau est constitué dans la perspective de l'étude de la liaison entre deux variables catégorielles: Quels sont les candidats "préférés" dans un département ?
Principe
Le principe de ces méthodes est de partir sans a priori sur les données et de les décrire en analysant la hiérarchisation de l'information présente dans les données. Pour ce faire, les analyses factorielles étudient l'inertie du nuage de points ayant pour coordonnées les valeurs présentes sur les lignes du tableau de données.
La "morphologie du nuage" et la répartition des points sur chacun de ces axes d'inertie permettent alors, de rendre lisible et hiérarchisée l'information contenue dans le tableau. Mathématiquement, après avoir centré et réduit le tableau de données que l'on a affecté d'un système de masse (par exemple, les sommes marginales de chaque ligne), on calcule la matrice d'inertie associée et on la diagonalise (la répartition de l'information selon les différents axes est représentée par l'histogramme des valeurs propres). On effectue alors un changement de base selon ses vecteurs propres, c'est-à-dire selon les axes principaux d'inertie du nuage de points. On projette alors les points figurant chaque ligne sur les nouveaux axes. L'ensemble de l'information est conservée, mais celle-ci est maintenant hiérarchisée, axe d'inertie par axe d'inertie. L'histogramme des valeurs propres permet de voir le type de répartition de l'information entre les différents axes et l'étendue en dimension de celle-ci.
Le premier axe d'inertie oppose les points, c'est-à-dire les lignes du tableau ayant les plus grandes distances ou "différences". La première valeur propre d'inertie, (associée à ce premier axe) mesure la quantité d'information présente le long de cet axe, c'est-à-dire dans cette opposition. On analyse ainsi les différents axes, en reconstituant progressivement la totalité des données.
Plusieurs méthodes d'analyse des correspondances existent, qui diffèrent par le type de représentation de l'information, c'est-à-dire de métrique, ou de système de masse qu'elles utilisent.
L'analyse factorielle des correspondances AFC développée par Jean-Paul Benzecri et ses collaborateurs emploie la métrique du chi-deux : chaque ligne est affectée d'une masse qui est sa somme marginale, le tableau étudié est le tableau des profils des lignes, ce qui permet de représenter dans le même espace à la fois les deux nuages de points associés aux lignes et aux colonnes du tableau de données ; elle est par ailleurs très agréablement complétée par des outils de classification ascendante hiérarchique (CAH) qui permettent d'apporter des visions complémentaires, en particulier en construisant des arbres de classification des lignes ou des colonnes.
Pour chaque point représentatif des lignes ou des colonnes du tableau de données, nouvel axe par nouvel axe, on s'intéresse à ses nouvelles coordonnées, au cosinus carré de l'angle avec l'axe (ce qui est équivalent à un coefficient de corrélation), ainsi qu'à sa contribution à l'inertie expliquée par l'axe (c'est-à-dire à sa contribution à la création de l'axe).
Deux contraintes particulières sur les données sont à signaler : d'une part, les tableaux ne peuvent comporter de cases vides et d'autre part, seules des valeurs positives sont permises. De plus, compte tenu de la métrique du chi-deux employée par l'AFC, cette méthode accorde une importance plus grande aux lignes de somme marginale élevée. Si nous utilisons des tableaux quantitatifs et souhaitons équilibrer la contribution de chaque ligne au calcul de l'inertie, nous devons transformer le tableau pour assurer à chaque ligne une somme marginale égale. Pour ce faire, on peut dédoubler chaque ligne, en lui adjoignant un tableau de complément. A chaque valeur fij, on fait correspondre une valeur dédoublée k-fij, avec k>=max(fij).
Par l'AFC, il est tout autant possible d'analyser des tableaux contenant des mesures quantitatives que des indications qualitatives, (par exemple une donnée "couleur"), ces deux types ne pouvant être mélangés. Un cas particulier de la deuxième catégorie de tableau est constituée par les tableaux "disjonctifs" ; plusieurs variables constituent les colonnes : elles sont toutes découpées en plusieurs modalités, dont une et une seule est vraie par individu. Lors d'une analyse factorielle, on peut rajouter des données "supplémentaires", c'est-à-dire que l'on ne fait pas intervenir dans le calcul de l'inertie, mais que l'on projette sur les axes.

















































