Analyse fréquentielle - Définition
L'analyse fréquentielle, ou analyse de fréquences, est une méthode de cryptanalyse découverte par Abu Yusuf Ya'qub ibn Is-haq ibn as-Sabbah Oòmran ibn Ismaïl al-Kindi au IXe siècle et fut concrétisée par Charles Babbage au XIXe siècle. Elle consiste à examiner la fréquence des lettres employées dans un message chiffré. Cette méthode est fréquemment utilisée pour décoder des messages chiffrés par substitution (comme par exemple le Chiffre de Vigenère ou le Chiffre de César).
L'analyse fréquentielle est basée sur le fait que, dans chaque langue, certaines lettres ou combinaisons de lettres apparaissent avec une certaine fréquence. Par exemple, en français, le e est la lettre la plus utilisée, suivie du s et du a. Inversement, le w est peu usité.
Ces informations permettent aux cryptanalystes de faire des hypothèses sur le texte clair, à condition que l'algorithme de chiffrement conserve la répartition des fréquences, ce qui est le cas pour des substitutions mono-alphabétiques et poly-alphabétiques. Une deuxième condition est nécessaire pour appliquer cette technique : c'est la longueur du message à décrypter. En effet, un texte trop court ne reflète pas obligatoirement la répartition générale des fréquences des lettres. De plus, si la clé est de la même longueur que le message, il ne pourra y avoir des répétitions de lettres et l'analyse fréquentielle sera impossible.
Découverte
L'analyse fréquentielle a été découverte au IXe siècle par al-Kindi.

Il expose les fondements de cette méthode de cryptanalyse dans son traité intitulé Manuscrit sur le déchiffrement des messages cryptographiques. Il découvre qu'un message chiffré conserve la trace du message clair original en gardant les fréquences d'apparitions de certaines lettres.
L'analyse de fréquences sera réinventée par Charles Babbage au XIXe siècle pour permettre le déchiffrement du Chiffre de Vigenère réputé à cette époque incassable. Sa découverte restera inusitée pendant près d'un siècle.
Principe
Fréquence d'apparition des lettres en fonction de la langue
On peut constater que selon la langue, un texte comportera une répartitions particulières des fréquences de lettres. Par exemple en français les lettres les plus fréquentes, c’est-à-dire les lettres que l'on trouve le plus souvent, sont le E, suivi du A, du I et du S ... On obtient la répartition de fréquences des lettres suivante (en %) :
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | |
| Français | 9,42 | 1,02 | 2,64 | 3,39 | 15,87 | 0,95 | 1,04 | 0,77 | 8,41 | 0,89 | 0,00 | 5,34 | 3,24 | 7,15 | 5,14 | 2,86 | 1,06 | 6,46 | 7,90 | 7,26 | 6,24 | 2,15 | 0,00 | 0,30 | 0,24 | 0,32 |
| Anglais | 8.08 | 1.67 | 3.18 | 3.99 | 12.56 | 2.17 | 1.80 | 5.27 | 7.24 | 0.14 | 0.63 | 4.04 | 2.60 | 7.38 | 7.47 | 1.91 | 0.09 | 6.42 | 6.59 | 9.15 | 2.79 | 1.00 | 1,89 | 0,21 | 1,65 | 0,07 |
Cette répartition des fréquences des lettres n'est qu'approximative, cela dépend de nombreux paramètres tels que le niveau de langue du texte, ainsi que du style d'écriture (Par exemple un message militaire utilisera souvent de nombreuses abréviations). On peut aussi analyser la fréquence des bigrammes dans un texte, c’est-à-dire la fréquence des groupes de deux lettres. Cela amenera des indices importants pour décrypter un texte chiffré car on sait que l'on ne pourra trouver des bigrammes tels que XK ou WX dans le texte clair.
Application au jeu du Scrabble
On peut remarquer que ces fréquences correspondent à peu de choses près aux distributions des lettres dans le jeu du Scrabble, celle-ci rapportant plus ou moins de points en fonction de leur fréquence d'utilisation. En effet, la répartition des lettres avec le nombre de points correspondant est la suivante :
| A1 | B3 | C3 | D2 | E1 | F4 | G2 | H4 | I1 | J8 | K10 | L1 | M2 | N1 | O1 | P3 | Q8 | R1 | S1 | T1 | U1 | V4 | W10 | X10 | Y10 | Z10 |
| 9 | 2 | 2 | 3 | 15 | 2 | 2 | 2 | 8 | 1 | 1 | 5 | 3 | 6 | 6 | 2 | 1 | 6 | 6 | 6 | 6 | 2 | 1 | 1 | 1 | 1 |
La répartition des lettres du premier exemplaire du jeu du Scrabble a d'ailleurs été faite par analyse statistique du New York Times.
Déchiffrement d'un texte codé par un chiffrement monoalphabétique à l'aide de l'analyse fréquentielle
La répartition des fréquences obtenues peut être utilisée pour décrypter un message codé par un chiffre de substitution. En effet, si l'on découvre une lettre très fréquente dans le message chiffré, il s'agira sans doute de la lettre E dans le message clair car c'est la lettre la plus courante en français. Nous pouvons ensuite en déduire les autres lettres en étudiant toute les fréquences des lettres du message chiffré. Par exemple, considérons le message chiffré suivant :
- segelazew aop qj lnkfap z ajyuyhklazea cnwpqepa aynepa ykklanwperaiajp
Il faut donc calculer les fréquences d'apparition de chacune des lettres du message chiffré afin de les comparer à la répartition normale des fréquences des lettres en français. On obtient la répartition des fréquences (en %) suivante pour ce message chiffré :
| Lettres | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | |
| Occurrences | 12 | 0 | 1 | 0 | 7 | 1 | 1 | 1 | 1 | 3 | 4 | 4 | 0 | 4 | 1 | 7 | 2 | 1 | 1 | 0 | 1 | 0 | 3 | 0 | 4 | 3 | 62 |
| Fréquences | 19,4 | 0 | 1,6 | 0 | 11,3 | 1,6 | 1,6 | 1,6 | 1,6 | 4,8 | 6,5 | 6,5 | 0 | 6,5 | 1,6 | 11,3 | 3,2 | 1,6 | 1,6 | 0 | 1,6 | 0 | 4,8 | 0 | 6,5 | 4,8 | 100 |
Nous pouvons donc constater que c'est la lettre A qui est la plus fréquente dans le message chiffré. Celle-ci a donc de grande chance de représenter la lettre E dans le message clair, car c'est la lettre la plus courante en français. Le E et le P sont également fréquents dans le texte chiffré, ils représentent donc sûrement les lettres S ou A du texte clair. Ces suppositions nous amènent à retrouver une partie du texte non chiffré, ce qui va permettre de déduire à partir de ces quelques lettres une partie de la clé. Dans le cas d'un chiffre de substitution monoalphabétique, nous pouvons avoir affaire à un chiffrement de César, nous obtiendrons alors dans ce cas un décalage de 4 lettres puisque l'on a supposé A=E. Muni de cette clé, nous pouvons décrypter le reste du message, ce qui nous donne :
Ce message est cohérent, nos suppositions de départ étaient exactes.
Déchiffrement d'un texte codé par un chiffrement polyalphabétique à l'aide de l'analyse fréquentielle
Pour déchiffrer un texte codé par un chiffrement polyalphabétique, on commence par former une hypothèse sur le nombre de caractères de la clé (que nous appelerons n), par exemple grâce à un calcul d'indice de coïncidence. À partir de cette hypothèse, nous en déduisons que tous les n caractères du messages sont codés à partir de la même lettre clé.
Applications
L'analyse fréquentielle est à la base de la cryptanalyse. Elle a notamment permis le déchiffrement du chiffre de Vigenère et de bien d'autres codes fondés sur un principe similaire. Mais l'analyse fréquentielle a également permis le déchiffrement et la compréhension du linéaire B, qui est une langue ancienne inusitée de nos jours.
Limites
L'analyse fréquentielle ne peut être utilisée que pour des codes de substitutions simples (elle est par exemple inefficace contre les codes RSA et DES). Elle ne fonctionne pas pour les codes dits de transposition, qui changent la place des lettres ou des symboles dans le message. Pour savoir si l'on a affaire à un code de substitutions, on peut utiliser l'indice de coïncidence avant l'analyse fréquentielle. Cela nous permettra également d'avoir une longueur de mot clé conseillée qui pourra nous servir de base pour l'analyse statistique.
L'analyse de fréquences ne peut pas non plus être usitée si la longueur du message est très faible, car la clé se répétera très peu et nous ne pourrons observer de particularités dans la fréquence des lettres. C'est aussi pour cette raison que l'on ne peut pas décrypter un message codé avec une longueur de clé égale à celle du message, car on pourrait aboutir à plusieurs textes possibles pour le même message chiffré ! Nous ne pouvons donc pas dans ce cas précis déterminer le sens général du message, c'est le principe du masque jetable qui garantit un message réellement indécryptable.
Pour se prémunir d'une cryptanalyse par analyse fréquentielle, il existe plusieurs parades utilisées dans les algorithmes de chiffrements. On peut utiliser un chiffre qui attribue plusieurs symboles pour une seule lettre, en fonction de sa fréquence (Par exemple, on utilisera 4 ou 5 symboles pour le E mais un seul pour le K). On dit alors que l'on utilise un code homophonique.
Nous pouvons également utiliser le surchiffrement, qui consiste à recoder le texte chiffré pour ne pas permettre de faire des hypothèses sur les lettres les plus fréquentes. Un texte surchiffré sera donc plus difficile à déchiffrer.
L'analyse fréquentielle en littérature
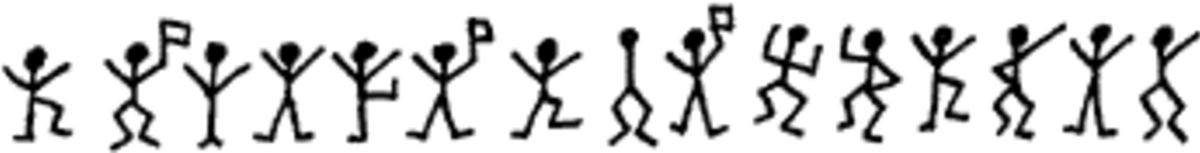
L'analyse fréquentielle est une technique de cryptanalyse fréquemment relatée dans les fictions. On la retrouve par exemple dans Le scarabée d'or d'Edgar Allan Poe ou dans Les Hommes dansants, une aventure de Sherlock Holmes écrite par Arthur Conan Doyle. Dans cette dernière énigme, les messages étaient alors codés avec différents symboles, en forme de personnages dansants.
Bibliographie
- Simon Singh, Histoire des codes secrets, Edition J.C. Lattès, 1999

















































