Régression linéaire - Définition
La liste des auteurs de cet article est disponible ici.
Démonstration des formules grâce aux espaces vectoriels de dimension n
Dans l'espace

On peut remarquer que :





On note alors




Le vecteur Z de coordonnées (ax1 + b,ax2 + b,...,axn + b) appartient à l'espace vectoriel engendré par X et U.
La somme

Cette norme est minimale si et seulement si Z est le projeté orthogonal de Y dans l'espace vectoriel vect(X,U).
Z est le projeté de Y dans l'espace vectoriel vect(X,U) si et seulement si (Z − Y).U = 0 et

Or


En remplaçant dans



Enfin le coefficient de corrélation linéaire s'écrit alors



On retrouve alors les résultats suivants:
- si le coefficient de corrélation linéaire est 1 ou -1, les vecteurs
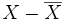
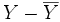
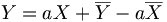
- si le coefficient de corrélation linéaire est en valeur absolue supérieur à



Démonstration des formules par étude d'un minimum
1ère étape : détermination de b
Pour tout réel a, on pose


Ce polynôme atteint son minimum en

Ce qui signifie que la droite passe par le point moyen G
Il reste à remplacer dans la somme de départ, b par cette valeur.
2ème étape : détermination de a
Pour tout réel a,


-
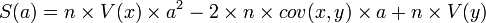

Ce polynôme atteint son minimum en
La droite de régression est bien la droite passant par G et de coefficient directeur

Généralisation: le cas matriciel
Lorsqu'on dispose de plusieurs variables explicatives dans une régression linéaire, il est souhaitable d'avoir recours aux notations matricielles. Si l'on dispose d'un jeu de n données (yi)i = 1..n que l'on souhaite expliquer par k variables explicatives (y compris la constante)


La régression linéaire s'exprime sous forme matricielle:

et il est question d'estimer le vecteur de coefficients k × 1

Son estimateur par moindre carré est:

Il faut que la matrice X soit de plein rang (


L'estimation de la matrice (symétrique) de variance-covariance de cet estimateur est:

Le terme


La qualité de l'ajustement linéaire se mesure encore par un coefficient de corrélation R2, défini ici par:

où SCR (respectivement SCT) représente la somme des carrés des résidus (respectivement la somme des carrés totaux). Ces sommes s'écrivent



















































