Regroupement hiérarchique - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
Dans le domaine informatique, et plus précisément dans le domaine de l'analyse et de la classification automatique de données, la notion de regroupement hiérarchique recouvre différentes méthodes de clustering, c'est-à-dire de classification par algorithme de classification.
La classification ascendante hiérarchique
C'est une méthode de classification automatique utilisée en analyse des données ; à partir d'un ensemble Ω de n individus, son but est de répartir ces individus dans un certain nombre de classes.
La méthode suppose qu'on dispose d'une mesure de dissimilarité entre les individus; dans le cas de points situés dans un espace euclidien, on peut utiliser la distance comme mesure de dissimilarité. La dissimilarité entre des individus x et y sera notée dissim(x,y).
La classification ascendante hiérarchique est dite ascendante car elle part d'une situation où tous les individus sont seuls dans une classe, puis sont rassemblés en classes de plus en plus grandes. Le qualificatif "hiérarchique" vient du fait qu'elle produit une hiérarchie H, l'ensemble des classes à toutes les étapes de l'algorithme, qui vérifie les propriétés suivantes:
-
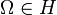
-
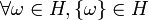
-
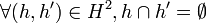
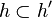
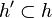





Algorithme
Principe
Initialement, chaque individu forme une classe, soit n classes. On cherche à réduire le nombre de classes à nbclasses < n, ceci se fait itérativement. A chaque étape, on fusionne deux classes, réduisant ainsi le nombre de classes. Les deux classes choisies pour être fusionnées sont celles qui sont les plus "proches", en d'autres termes, celles dont la dissimilarité entre elles est minimale, cette valeur de dissimilarité est appelée indice d'agrégation. Comme on rassemble d'abord les individus les plus proches, la première itération a un indice d'agrégation faible, mais celui va croître d'itération en itération.
Mesure de dissimilarité inter-classe
La dissimilarité de deux classes C1 = x,C2 = y contenant chacune un individu se définit simplement par la dissimilarité entre ces individus. dissim(C1,C2) = dissim(x,y)
Lorsque les classes ont plusieurs individus, il existe de multiples critères qui permettent de calculer la dissimilarité. Les plus simples sont les suivants:
- Le saut minimum retient le minimum des distances entre individus de C1 et C2:
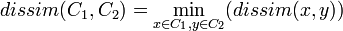
- Le saut maximum est la dissimilarité entre les individus de C1 et C2 les plus éloignés:
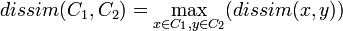
- Le lien moyen consiste à calculer la moyenne des distances entre les individus de C1 et C2:
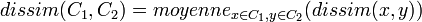
- La distance de Ward vise à maximiser l'inertie inter-classe:
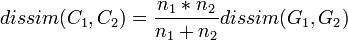




Implémentation en pseudo-code
Entrées:
- individus: liste d'individus
- nbClasses: nombre de classes qu'on veut obtenir au final
Sortie:
Pour i=1 à individus.longueur Faire classe.ajouter(nouvelle classe(individu[i])); Fin Pour Tant Que classes.longueur > nbClasses Faire // Calcul des dissimilarités entre classes dans une matrice triangulaire supérieure matDissim = nouvelle matrice(classes.longueur,classes.longueur); Pour i=1 à classes.longueur Faire Pour j=i+1 à classes.longueur Faire matDissim[i][j] = dissim(classes[i],classes[j]); Fin Pour Fin Pour // Recherche du minimum des dissimilarités Soit (i,j) tel que matDissim[i][j] = min(matDissim[k][l]) avec 1<=k<=classes.longueur et k+1<=l<=classes.longueur; // Fusion de classes[i] et classes[j] Pour tout element dans classes[j] Faire classes[i].ajouter(element); Fin pour supprimer(classes[j]); Fin Tant Que