Maximum de vraisemblance - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
L'estimation du maximum de vraisemblance est une méthode statistique courante utilisée pour inférer les paramètres de la distribution de probabilité d'un échantillon donné.
Cette méthode a été développée par le statisticien et généticien Ronald Fisher entre 1912 et 1922.
L'estimateur du maximum de vraisemblance peut exister et être unique, ne pas être unique, ou ne pas exister.
Définitions
Soit X une variable aléatoire réelle, de loi ou bien discrète ou bien continue, dont on veut estimer un paramètre θ. On note


fθ(x) représente la densité de X (où θ apparaît) et Pθ(X = x) représente une probabilité discrète (où θ apparaît).
On appelle vraisemblance de θ au vu des observations (x1,...,xi,...,xn) d'un n-échantillon indépendamment et identiquement distribué selon la loi

On cherche à trouver le maximum de cette vraisemblance pour que les probabilités des réalisations observées soient aussi maximum. Ceci est un problème d'optimisation. On utilise généralement le fait que si L est dérivable (ce qui n'est pas toujours le cas) et si L admet un maximum global en une valeur

Ainsi en pratique :
- La condition nécessaire

ou

permet de trouver la valeur
-
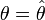

ou

Pour simplifier, dans les cas de lois continues, où parfois la densité de probabilité est nulle sur un certain intervalle, on peut omettre d'écrire la vraisemblance pour cet intervalle uniquement.
Propriétés
L'estimateur obtenu par la méthode du maximum de vraisemblance est :
- convergent, mais il peut être biaisé en échantillon fini.
- asymptotiquement efficient, il atteint la borne de Cramer Rao.
- asymptotiquement distribué selon une loi normale.
Généralisation
Pour une variable aléatoire réelle X de loi quelconque définie par une fonction de répartition F(x), on peut considérer des petits voisinages V autour de (x1,..., xn) dans

![L(\theta; V) = P[(X_{1,\theta}, ..., X_{n,\theta}) \in V]](https://static.techno-science.net/illustrationWebp/Definitions/autres/5/567f5aa80eafc2c36b1bb917c00d4932_13e4c9c05e6f52251358896fca53bca4.png)



On retombe sur les fonctions de vraisemblance précédentes quand X est à loi discrète ou continue.
Exemples
Avec une loi discrète
On souhaite estimer le paramètre λ d'une loi de Poisson à partir d'un n-échantillon.

L'estimateur du maximum de vraisemblance est :

La vraisemblance s'écrit :


La vraisemblance étant positive, on considère son Logarithme naturel :



La dérivée première s'annule quand :



La dérivée seconde s'écrit :

Ce ratio étant toujours négatif alors, l'estimation est donnée par :

Il est tout à fait normal de retrouver dans cet exemple didactique la moyenne empirique, car c'est le meilleur estimateur possible pour le paramètre λ (qui représente aussi l'espérance d'une loi de Poisson).
Avec une loi continue
Loi exponentielle
On souhaite estimer le paramètre α d'une loi exponentielle à partir d'un n-échantillon.

L'estimateur du maximum de vraisemblance est :

La vraisemblance s'écrit :


La vraisemblance étant positive, on considère son logarithme népérien:


La dérivée première s'annule quand :



La dérivée seconde s'écrit :

Ce ratio est toujours négatif donc l'estimation est donnée par:

Là encore, il est tout à fait normal de retrouver l'inverse de la moyenne empirique, car on sait que l'espérance d'une loi exponentielle correspond à l'inverse du paramètre α.
Loi normale
L'estimateur du maximum de vraisemblance de l'espérance μ et la variance σ2 d'une loi normale est:


Une loi normale


la fonction de vraisemblance pour un échantillon de n valeurs indépendantes :

qui peut s'écrire plus simplement (voir Théorème de König-Huyghens):

où

Nous avons là deux paramètres: θ = μ,σ2, donc il faut maximiser la fonction

On va donc chercher la dérivée première et l'égaliser à zéro.
En l'occurrence, c'est la fonction de log-vraisemblance qui est maximisée ici.



et on obtient donc l'estimateur par le maximum de vraisemblance de l'espérance:

On peut montrer en plus que cet estimateur sans biais:
![\mathbb{E} \left[ \widehat\mu \right] = \mu](https://static.techno-science.net/illustrationWebp/Definitions/autres/e/e7f1c2d90a52b5ed61816b5bdcc6dd1f_6d765a0dbaf6f2a5699da17a20397ebb.png)
Pour le second paramètre, σ, on cherche par analogie le maximum en fonction de σ.



donc

et on obtient finalement l'estimateur par le maximum de vraisemblance de la variance:

L'estimateur de la variance est par contre biaisé :
![\mathbb{E} \left[ \widehat{\sigma^2} \right]= \frac{n-1}{n}\sigma^2](https://static.techno-science.net/illustrationWebp/Definitions/autres/3/3304734a305c201b30d3881f0604d557_043b05809effacc6479b4b0be3defebc.png)
L'estimateur de la variance est un bon exemple pour montrer que le maximum de vraisemblance peut fournir des estimateurs biaisés : un estimateur sans biais est donné en effet par:


Si la dérivée ne s'annule jamais
On souhaite estimer le paramètre a d'une loi uniforme à partir d'un n-échantillon.
![f(x,a) = f_a(x) = \begin{cases} \frac {1}{a} & \text{si} \quad x \in [0;a] \\ 0 & \text{sinon} \end{cases}](https://static.techno-science.net/illustrationWebp/Definitions/autres/d/df208ba1b5091eeb99471a1e0fbe8797_27e013316f2ddd42d3d53396bbda885d.png)
La vraisemblance s'écrit :

Intuitivement, il est clair que cette expression de la vraisemblance ne s'annule jamais (on peut la dériver pour s'en convaincre). Graphiquement dans le repère (a, L), sa représentation est une courbe décroissante de type « inverse » (convexe tournée vers l'origine).
La valeur de L sera maximale quand a sera très près de 0, donc quand a sera le plus petit possible (l'intervalle de la densité est alors réduit). Mais, pour que la densité soit vraie, le paramètre a doit être nécessairement plus grand que tous les xi de l'échantillon.
On prend donc comme valeur qui maximise L, tout en vérifiant la définition de la loi de probabilité :

Wn = A = max(X1,...,Xn)
Cet exemple permet de montrer, qu'un estimateur n'est pas toujours défini par une expression numérique explicite. Ainsi on sera amené parfois à considérer le maximum ou le minimum des échantillons.

















































