Glossaire du data mining - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
La Fouille de données étant à l'intersection des domaines de la Statistique, de l'Intelligence artificielle et des Bases de données, il semble judicieux de faire un glossaire où on peut retrouver les définitions des termes en français et leur équivalent en anglais, classées selon ces trois domaines.
Termes
Bases de données
| Sommaire : | - |
|---|
Dans ce paragraphe est listé le vocabulaire spécifique aux bases de données et utilisé dans le data mining.
C
Champs (« Field ») :
R
Règle d'Association (« Association Rule ») : Une règle de la forme Si ceci alors cela qui associe des évènements dans une base de données.Exemple les associations entre les objets achetés dans un supermarché.
S
Système de Gestion de Base de données (DBMS) (« Database Management System (DBMS) ») : Un système de gestion de base de données est l'ensemble des programmes qui contrôlent la création, l'évolution et l'utilisation d'une base de données.
Data Mining
| Sommaire : | - |
|---|
Dans ce paragraphe est listé le vocabulaire spécifique au data mining ainsi que les algorithmes utilisé dans le data mining et issus d'autres domaines.
A
CART (« Classification and Regression Trees ») : Un type d'algorithme d'arbre de décision qui automatise le processus d'élagage par validation croisée et autre techniques.
Arbre de décision (« Decision Tree ») : Une classe de méthodes Statistiques et d'exploration de données (« Data Mining ») qui forment des modèles prédictifs en forme d'arbre.
Arbre de classification (« Classification Tree ») : c'est une technique de data mining utilisée pour prédire l'appartenance de données à des classes de telles manière que les données dans une classe se ressemblent le plus possible alors que les classes elle-mêmes soient le plus dissemblables possible. Les critères de séparation peuvent être le χ², l'indice de Gini, le Twoing, l'Entropie...
C
Classification (« Clustering ») : C'est la technique qui consiste à regrouper les enregistrements en fonction de leur proximité et de la connectivité à l'intérieur d'un espace à n dimensions. Dans ce cas, c'est une technique d'apprentissage non-supervisée. La Classification est aussi le processus permettant de déterminer qu'un enregistrement appartient à un groupe prédéterminé. Il s'agit alors d'une technique d'apprentissage supervisée. En français on parle aussi de Segmentation, en anglais on parle de « Clustering » pour cet aspect de la Classification.
CHAID (« Chi-Square Automatic Interaction Detector ») : Un processus qui utilise des tables d'éventualités et le test du chi2 pour créer un arbre.
D
Data binning (« Binning ») : Processus par lequel un grandeur continue est discrétisée, découpée en morceaux.
E
Entropie (« Entropy ») : Souvent utilisée en « Data Mining », elle permet de mesurer le désordre dans un ensemble de données. Pour un ensemble discret de k valeurs on a

Exactitude (« Accuracy ») : L'exactitude d'un système de mesures d'une grandeur est sa capacité a être proche de la vraie valeur de cette grandeur (voir précision).
Extraction de Connaissances (« Knowledge Discovery ») : une autre expression signifiant Data Mining.
G
Gini (« Gini Metric ») : Un indicateur permettant de mesurer la réduction du désordre dans un ensemble de données induite par la séparation des données dans un arbre de décision. L'indice de diversité de Gini et l'entropie sont les deux manières les plus populaire pour choisir les prédicteurs dans l'arbre de décision CART. Pour un ensemble discret de k valeurs on a

I
ID3 (« ID3 ») : ID3 est l'un des plus anciens algorithmes d'arbre de décision
M
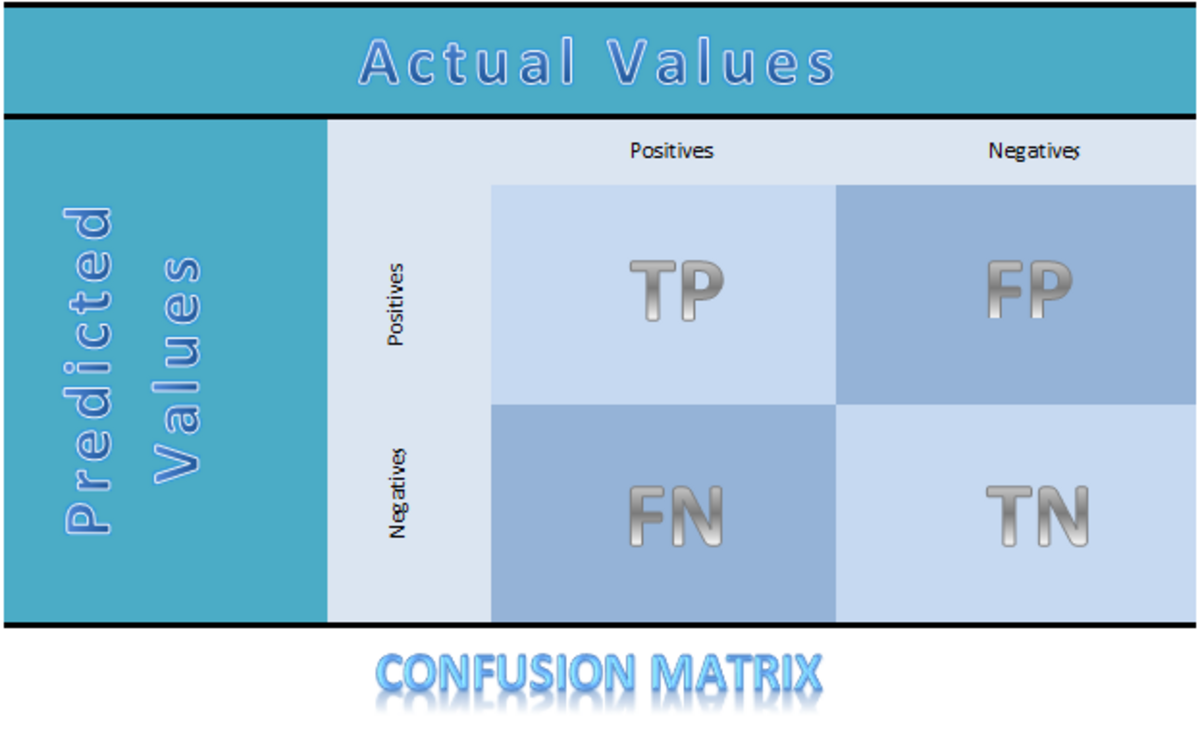
Matrice de Confusion (« Confusion Matrix ») : c'est un tableau dans lequel on place les compteurs des valeurs que le test (ou modèle) a prédit correctement dans la case des "Vrai Corrects" ou des "Faux Corrects", celles des valeurs que le test (ou modèle) n'a pas prédit correctement dans la case des "Vrais Incorrects" ou "Faux Incorrects" ( dans l'exemple ci-contre on voit les True Positive, True Negative, False Positive et False Negative). On calcule ensuite l'Exactitude, la Sensibilité, L'Efficacité, la Spécificité pour mesurer la pertinence dut test ou du modèle.
P
Précision ( « Précision ») : La précision d'un système de mesures d'une grandeur est sa capacité à donner des résultats proches lorsqu'ils sont répétés sous conditions inchangées.
Q
QUEST ( « QUEST ») : un arbre de décision/classification développé par Wei-Yin Loh et Yu-Shan Shih en 1997. QUEST est utilisé dans le package lohTools du logiciel R.
R
Règle d'associations ( « Association rules ») : Une technique de data mining utilisée pour décrire des relations entre des objets. L'algorithme A-priori est un algorithme efficace et populaire pour trouver ce type de règles d'association.
V
Variable catégorielle ( « categorical variable ») : variable pouvant prendre un nombre restreint de valeurs, comme les couleurs par exemple. On parle aussi de variable discrète.
Variable continue ( « Continuous variable ») : variable pouvant prendre un nombre infini de valeurs, comme un prix par exemple.
Variable dépendante ( « Dependent variable ») : variable cible ou variable à expliquer dont on veut estimer les valeurs en fonctions d'autres variables dites explicatives. On parle aussi de variable cible ou variable réponse .
Variable indépendante ( « Independent variable ») : variable explicative permettant d'estimer une variable cible. On parle aussi de variable explicative, de contrôle, réponse.
Intelligence artificielle
| Sommaire : | - |
|---|
Dans ce paragraphe est listé le vocabulaire spécifique à l'intelligence artificielle et les concepts issus de l'IA et utilisés dans le data mining.
A
Algorithme génétique (« Genetic algorithm ») : C'est un algorithme de recherche heuristique inspiré de l'évolution naturelle. Il est employé dans le domaine de la recherche de solutions approchées dans les problèmes d'optimisation. Il utilise des techniques comme l'héritage, la mutation, la sélection et l'enjambement.
B
Bagging (« Bagging ») : ou « Bootstrap aggregating » est un ensemble d'algorithmes destinés à l'amélioration de l'exactitude (voir ci-dessus) de la classification et/ou la Régression d'un modèle en apprentissage automatique.
F
Feuille (« leaf ») : Dans un arbre de classification, tout nœud qui n'est pas segmenté.
Forêt d'arbres décisionnels (« Random forest ») :
« Les Forêts d'arbres décisionnelles sont formées d'une combinaison d'arbres estimateurs tels que chaque arbre dépend des valeurs d'un vecteur aléatoire échantillonné indépendament et ayant la même distribution pour tous les arbres de la forêt. »
— Leo Breiman, Random Forests
I
Intelligence artificielle (« Artificial Intelligence ») : Le domaine scientifique qui a pour but la création de comportements intelligents dans une machine.
N
Nœud racine (« Root node ») : le début d'un arbre de décision; le nœud racine détient l'ensemble des données avant qu'elles ne soient découpées dans l'arbre.
R
Règle de Hebb (« Hebbian Learning ») : Cette règle d'apprentissage des réseaux de neurones précise que les poids entre deux neurones augmentent quand ils sont excités simultanément et décroissent dans le cas contraire.
Réseaux de Kohonen (« Kohonen Networks ») : Un type de réseau de neurones où la localisation d'un nœud est calculée par rapport à ses voisin; la localité d'un nœud est très importante dans l'apprentissage; les réseaux de Kohonen sont souvent utilisés en clustering.
Réseaux Neuronaux (« Neural Network ») : Un modèle basé sur l'architecture du cerveau. Un réseau Neuronal consiste en multiples unités de calcul simples connectés par des poids adaptatifs.
Réseaux Neuronaux à base radiale « Radial basis function neural Network ») : c'est un réseau neuronal (voir ci-dessus) utilisant une couche cachée constituée de fonctions à base radiale, et une sortie combinaison linéaire des sorties des fonctions à base radiale. Ils sont caractérisés par un apprentissage rapide et un réseau compact.
Rétro-Propagation (« Back Propagation ») : Un des algorithmes d'apprentissage les plus usités pour la préparation des réseaux de neurones
Statistique
| Sommaire : | - |
|---|
Dans ce paragraphe est listé le vocabulaire spécifique aux statistiques et les concepts issus des statistiques et utilisés dans le data mining.
A
Analyse des données (« Exploratory Data Analysis ») : L'analyse des données est le processus qui consiste à examiner, nettoyer, transformer, et modéliser les données dans le but d'en extraire de l'information utile, de suggérer des conclusions, de prendre des décisions. Le Data mining est une technique spécifique d'analyse des données qui se concentre sur la modélisation et l'extraction de connaissances dans un but prédictif plutôt que descriptif, bien qu'une partie du processus de data mining nécessite la description des données.
Analyse Factorielle (« Factor Analysis ») : voir Analyse factorielle.
B
Boostrapping (« Bootstrap method ») : C'est une méthode de ré-échantillonnage permettant d'obtenir une distribution d'échantillons pour un paramètre, au lieu d'une seule valeur de l'estimation de ce paramètre.
C
Colinéarité (« Collinearity ») : Deux variables sont colinéaires si elles sont corrélées sans qu'une relation de cause ne soit établie entre elles.
Courbe de lift (« lift chart ») : c'est un résumé visuel de l'utilité des modèles statistiques et de data mining pour la prédiction d'une variable catégorielle. Elle sert à mesurer la performance d'un modèle. (voir courbe ROC et indice de Gini)
Courbe ROC (« ROC curve ») : La courbe ROC (« Receiver Operating Characteristics ») nous vient des ingénieurs US du traitement du signal qui l'ont inventée pendant la seconde guerre mondiale et depuis elle a été utilisée en médecine, radialogie, psychologie et maintenant en data mining. Sur l'axe des Y on représente les vrais évènements détectés et sur l'axe des X les faux évènements détectés (les erreurs de détection). Elle sert à mesurer la performance d'un estimateur ou d'un modèle.
E
Ensemble flou (« Fuzzy Set ») : Ils servent à modéliser la représentation humaines des connaissances.
F
Fonction base (« basis function ») : Fonction impliquée dans l'estimation de la Régression multivariée par spline adaptative (MARS). Ces fonctions forment une approximation des relations entre les estimateurs et les variables estimées.
I
Indépendance statistique (« Independence (statistical) ») : Deux évènements sont indépendants s'ils n'ont aucune influence l'un sur l'autre.

J
Jackknife (« Jackknife method ») : C'est une méthode de ré-échantillonnage, analogue à celle du bootstrapping, qui diffère de celle-ci seulement par la méthode de sélection des différents échantillons.
L
Logique floue (« Fuzzy Logic ») : La logique floue est une technique, formalisée par Lotfi Zadeh, utilisée en intelligence artificielle. Elle s'appuie sur les ensembles flous.
M
Modèle (« Model ») : Une description qui explique et prédit convenablement des données pertinentes mais qui est généralement moins volumineuse que les données elles-même.
S
Statistique Bayesienne (« Bayesian statistics ») : Une approche des statistiques fondée sur la loi de Bayes. Le théorème de Bayes exprime la probabilité de l'évènement A connaissant l'évènement B de la manière suivant :

.
T
Taux d'erreur (« Error Rate ») : Un nombre indiquant l'erreur faite par un modèle prédictif.
Test d'hypothèse (« Hypothesis Testing ») : voir Test d'hypothèse

















































