Corrélation (statistiques) - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
En probabilités et en statistique, étudier la corrélation entre deux ou plusieurs variables aléatoires ou statistiques numériques, c’est étudier l’intensité de la liaison qui peut exister entre ces variables. La liaison recherchée est une relation affine. Dans le cas de deux variables numériques, il s'agit de la régression linéaire.
Une mesure de cette corrélation est obtenue par le calcul du coefficient de corrélation linéaire. Ce coefficient est égal au rapport de leur covariance et du produit non nul de leurs écarts types. Le coefficient de corrélation est compris entre -1 et 1.
Droite de régression
Calculer le coefficient de corrélation entre 2 variables numériques revient à chercher à résumer la liaison qui existe entre les variables à l'aide d'une droite. On parle alors d'un ajustement linéaire.
Comment calculer les caractéristiques de cette droite ? En faisant en sorte que l'erreur que l'on commet en représentant la liaison entre nos variables par une droite soit la plus petite possible. Le critère formel le plus souvent utilisé, mais pas le seul possible, est de minimiser la somme de toutes les erreurs effectivement commises au carré. On parle alors d'ajustement selon la méthode des moindres carrés ordinaires. La droite résultant de cet ajustement s'appelle une droite de régression. Plus la qualité globale de représentation de la liaison entre nos variables par cette droite est bonne, et plus le coefficient de corrélation linéaire associé l'est également. Il existe une équivalence formelle entre les deux concepts.
Précautions à prendre
D'une manière générale, l'étude de la relation entre des variables, quelles qu'elles soient, doit s'accompagner de graphiques descriptifs, exhaustifs ou non dans l'appréhension des données à notre disposition, pour éviter de subir les limites purement techniques des calculs que nous utilisons. Néanmoins, dès qu'il s'agit de s'intéresser à des liaisons entre de nombreuses variables, les représentations graphiques peuvent ne plus être possibles ou être au mieux illisibles. Les calculs, comme ceux évoqués jusqu'à présent et donc limités par définition, nous aident alors à simplifier les interprétations que nous pouvons donner des liens entre nos variables, et c'est bien là leur intérêt principal. Il restera alors à vérifier que les principales hypothèses nécessaires à leur bonne lecture soient validées avant une quelconque interprétation.
Coefficient de corrélation linéaire de Bravais-Pearson
Formule

Par exemple, nous allons calculer le coefficient de corrélation entre deux séries de même longueur (cas typique : une régression). On suppose qu'on a les tableaux de valeurs suivants :



Si r vaut 0, les deux courbes ne sont pas corrélées. Les deux courbes sont d'autant mieux corrélées que r est loin de 0 (proche de -1 ou 1).
avec:
-
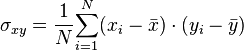

où

- et
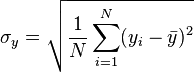



moyenne :
- Soit xi la valeur de la variable pour l'individu i.
-
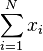


Interprétation
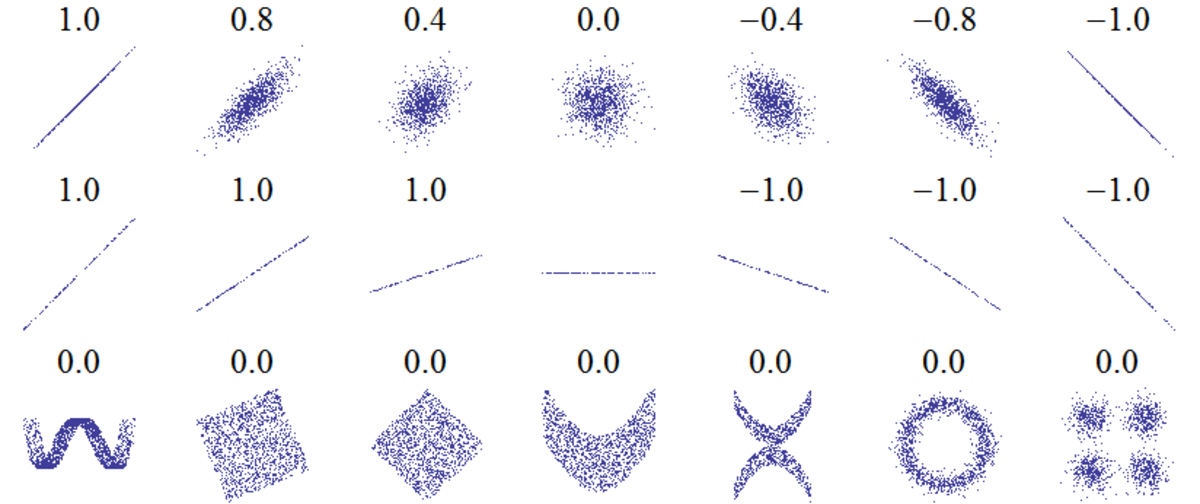
Il est égal à 1 dans le cas où l'une des variables est fonction affine croissante de l'autre variable, à -1 dans le cas où la fonction affine est décroissante. Les valeurs intermédiaires renseignent sur le degré de dépendance linéaire entre les deux variables. Plus le coefficient est proche des valeurs extrêmes -1 et 1, plus la corrélation entre les variables est forte ; on emploie simplement l'expression « fortement corrélées » pour qualifier les deux variables. Une corrélation égale à 0 signifie que les variables sont linéairement indépendantes.
Le coefficient de corrélation n’est pas sensible aux unités de chacune de nos variables. Ainsi, par exemple, le coefficient de corrélation linéaire entre l’âge et le poids d’un individu sera identique que l’âge soit mesuré en semaine, en mois ou en année(s).
En revanche, ce coefficient de corrélation est extrêmement sensible à la présence de valeurs aberrantes ou extrêmes (ces valeurs sont appelées des "déviants")dans notre ensemble de données (valeurs très éloignées de la majorité des autres, pouvant être considérées comme des exceptions).
Interprétation géométrique
Les deux séries de valeurs


Le cosinus de l'angle α entre ces vecteurs est donné par la formule suivante (produit scalaire normé) :

Donc cos(α) = rp
Le coefficient de corrélation n’est autre que le cosinus entre les deux vecteurs centrés !
- Si r = 1, l’angle α = 0, les deux vecteurs sont colinéaires (parallèles).
- Si r = 0, l’angle α = 90°, les deux vecteurs sont orthogonaux.
- Plus généralement : α = arccos(r), où arccos est la réciproque de la fonction cosinus.
Bien sûr, du point vue géométrique, on ne parle pas de « corrélation linéaire » : le coefficient de corrélation a toujours un sens, quelle que soit sa valeur entre -1 et 1. Il nous renseigne de façon précise, non pas tant sur le degré de dépendance entre les variables, que sur leur distance angulaire dans l’hypersphère à n dimensions.
Dépendance
Attention, il est toujours possible de calculer un coefficient de corrélation (sauf cas très particulier) mais un tel coefficient n'arrive pas toujours à rendre compte de la relation qui existe en réalité entre les variables étudiées. En effet, il suppose que l'on essaye de juger de l'existence d'une relation linéaire entre nos variables. Il n'est donc pas adapté pour juger de corrélations qui ne seraient pas linéaires et non linéarisables. Il perd également de son intérêt lorsque les données étudiées sont très hétérogènes puisqu'il représente une relation moyenne et que l'on sait que la moyenne n'a pas toujours un sens, notamment si la distribution des données est multi modale.
Si les deux variables sont totalement indépendantes, alors leur corrélation est égale à 0. La réciproque est cependant fausse, car le coefficient de corrélation indique uniquement une dépendance linéaire. D'autres phénomènes, par exemple, peuvent être corrélés de manière exponentielle, ou sous forme de puissance (voir série statistique à deux variables en mathématiques élémentaires).
Supposons que la variable aléatoire X soit uniformément distribuée sur l'intervalle [-1;1], et que Y = X2 ; alors Y est complètement déterminée par X, de sorte que X et Y ne sont pas indépendants, mais leur corrélation vaut 0.
Ces considérations sont illustrées par des exemples dans le domaine des statistiques.

| 
|

|
Relation de cause à effet
Une erreur courante est de croire qu'un coefficient de corrélation élevé induit une relation de causalité entre les deux phénomènes mesurés. En réalité, les deux phénomènes peuvent être corrélés à un même phénomène-source : une troisième variable non mesurée, et dont dépendent les deux autres. Le nombre de coups de soleil observés dans une station balnéaire, par exemple, peut être fortement corrélé au nombre de lunettes de soleil vendues ; mais aucun des deux phénomènes n'est probablement la cause de l'autre.

















































