Variables aléatoires élémentaires - Définition
La liste des auteurs de cet article est disponible ici.
Cas des variables aléatoires ayant une infinité dénombrable de valeurs
Ce cas sort du cadre des mathématiques élémentaires, mais mérite cependant d'être évoqué. Ces variables font le lien entre les variables discrètes prenant n valeurs, n grand, et les variables continues.
Il est possible de définir pX(xi) pour tout i de N.
Les lois les plus connues de variables aléatoires à valeurs dans N sont :
Variables aléatoires à densité
Il arrive que l’univers Ω soit infini et que l’univers X(Ω) soit aussi infini. Le calcul des pX(x) pour tout x de X(Ω) n’est souvent pas suffisant pour calculer la probabilité d’un événement et il est même fréquent que ces pX(x) soient tous nuls. Il est alors nécessaire de calculer directement pX([a ; b]).
Densité de probabilité
On dit que X est une variable aléatoire de densité f si la probabilité de l’événement « a ≤ X ≤ b » vaut

On peut remarquer que p([a ; a]) = 0, donc que p(]a ; b]) = p([a ; b]) ce qui explique la liberté prise dans ce cas avec les inégalités larges ou strictes.
De l'histogramme à la densité de probabilité
En renouvelant 10000 fois l'expérience X, on crée une série statistique continue. On peut alors ranger les différentes valeurs obtenues dans des classes de même amplitude et tracer l'histogramme des fréquences. L’aire du rectangle de base [xi, xi+1] représente la fréquence de la classe [xi, xi+1]. Cet histogramme dessine une fonction en escalier.
L'aire sous la courbe entre xi et xj représente la fréquence de la classe [xi, xj]. Or la loi des grands nombres nous dit que cette fréquence est une bonne approximation de p([xi, xj]). En multipliant les expériences et en affinant les classes, la fonction en escaliers se rapproche d'une fonction souvent continue, l'aire sous cette courbe sur l'intervalle [a ; b] est alors un bon représentant de la probabilité de l'intervalle [a ; b]. Cette fonction s'appelle la densité de probabilité de la variable X.
On prend souvent l’habitude de tracer cette densité de probabilité pour mieux visualiser la loi de probabilité associée en regardant l’aire sous la courbe entre les valeurs qui nous intéressent.
Loi uniforme
Le cas le plus simple de loi à densité est la loi uniforme. Les valeurs de X se répartissent uniformément sur un intervalle [a ; b]. L'histogramme que l'on pourrait dessiner serait une succession de rectangles de même hauteur. La densité de probabilité est donc une fonction constante k. L'aire sous la courbe sur l'intervalle [a ; b] vaut alors k(b - a). Or cette aire doit valoir 1, donc k = 1/(b-a).
La probabilité de l'intervalle [c ; d] (inclus dans [a ; b]) est alors k(d - c) =

Autres lois
On rencontre aussi
- La loi exponentielle dite aussi de durée de vie sans vieillissement
- La loi normale, dite aussi loi de Laplace-Gauss, ou loi normale gaussienne, ou loi de Gauss.
Ces deux lois sont également celles de distributions d’entropie maximale sous contrainte, la première quand la seule contrainte imposée est la moyenne, la seconde quand sont imposées une moyenne et une variance. Cette caractéristique montre leur caractère général : de toutes les distributions obéissant à ces contraintes, ce sont les moins prévenues, les moins arbitraires, les plus générales, bref, les plus neutres : celles qui n’introduisent pas d’information supplémentaire (et donc arbitraire) par rapport à ce qui est donné.
Espérance, variance et écart type
La méthode d’approximation d’une intégrale par la méthode des rectangles conduit à définir l’espérance et la variance comme des intégrales issues du passage à la limite des sommes définissant moyenne et variance dans le cas d’une variable statistique continue.
De la moyenne de la série statistique, on passe à l’espérance de X par la formule.
-
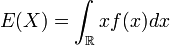

La variance s’écrit alors, par analogie avec la formule de la variance avec fréquences:
-
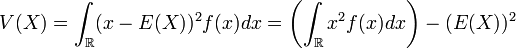

L’écart type reste toujours la racine carrée de la variance :

Fonction de répartition
La fonction de répartition est la fonction F définie sur R par F(x) = p(X ≤ x).
Dans le cas d’une variable à densité, c’est la primitive de f dont la limite en + ∞ est 1.
En effet

Médiane
Si la fonction de répartition F est continue et strictement croissante, elle définit une bijection de R sur ]0 ; 1[. Il existe donc alors une valeur unique M telle que F(M) = 1/2. Cette valeur s'appelle la médiane de la variable aléatoire X. Elle vérifie p(X ≤ M) = p(X > M) = 0,5.

















































