Détection automatique des publicités télévisées - Définition
La liste des auteurs de cet article est disponible ici.
Technique
Observations
Les techniques de détection font usage de plusieurs observations, supposées être caractéristiques des publicités, qui doivent en principe permettre la discrimination entre les programmes et les espaces de publicité diffusés. Ces observations sont ensuite combinées et utilisées de différentes manières afin de prendre une décision de traitement.
Images monochromes

L'observation la plus populaire est la présence de séparations, encore appelées cartons monochromes, ou simplement images monochromes. Ce sont des images monochromes qui sont diffusées par la chaîne entre deux publicités, essentiellement pour permettre au téléspectateur de mieux comprendre leur enchaînement. C'est une technique utilisée dans de nombreux pays : en Allemagne, aux États-Unis, en Irlande, aux Pays-Bas. Dans tous ces pays les images de séparation sont noires.
En France ces images existent aussi mais sont soit noires (Canal+,TF1) blanches (France 2, France 3, France 5), bleues (NT1) ou même avec le logo de la chaîne (NRJ12, M6, W9). En Asie, ou sur certaines chaînes irlandaises, ces images de séparations n'existent pas.
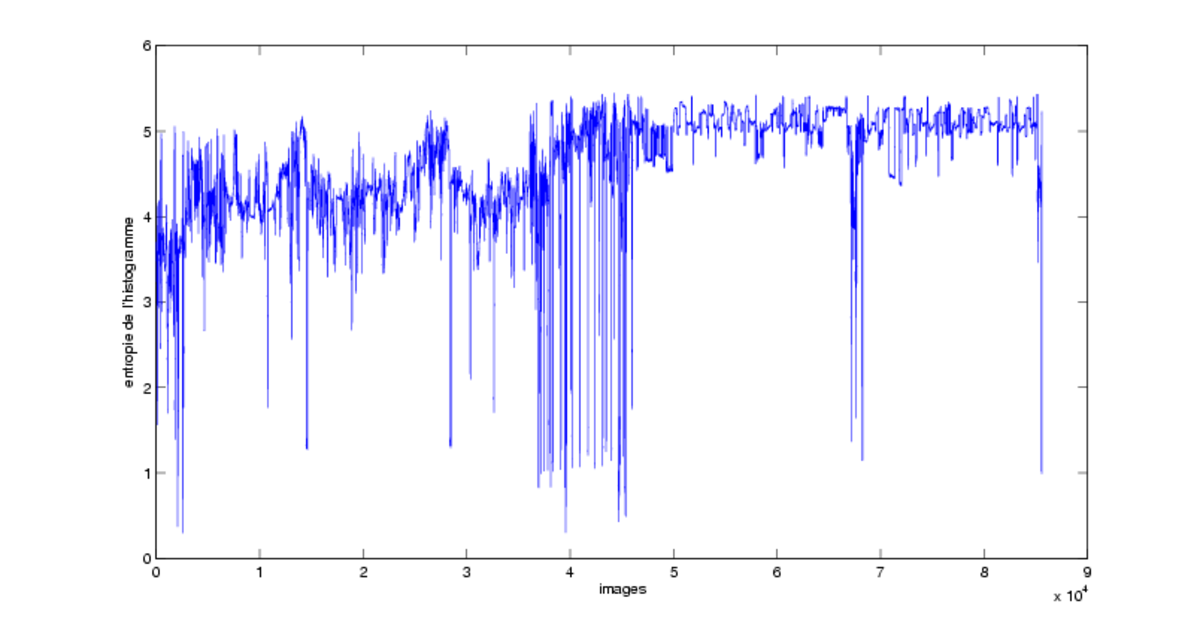
La détection d'images monochromes est un problème de traitement du signal simple. Toutefois le bruit de transmission et les scènes se déroulant de nuit compliquent la tâche. Plusieurs techniques ont été proposées : le seuillage de la moyenne et de la variance des pixels de luminance, l'entropie de l'histogramme de luminance.
Certains auteurs proposent de travailler dans le domaine compressé, en supposant que le flux vidéo est du MPEG-1 ou MPEG-2. Sadlier et al. proposent d'utiliser le coefficient DC de la matrice DCT de luminance d'un bloc 8×8, qui est la valeur moyenne des pixels de ce bloc. La détection des images noires est alors réalisée par un seuillage des valeurs de ce coefficient DC à partir d'une valeur moyenne de ce coefficient. Le même genre de méthode est utilisé par McGee et al., qui soulignent qu'une valeur de seuil fixe semble impraticable et réajustent cette valeur de seuil à chaque occurrence d'une image qui dépasse ledit seuil.
Ces techniques génèrent un grand nombre de faux positifs, parce qu'il existe énormément d'images « quasi-monochromes » qui ne sont pas des séparations de publicités, par exemple lors d'un fondu, ou dans les scènes de nuit.
Silence
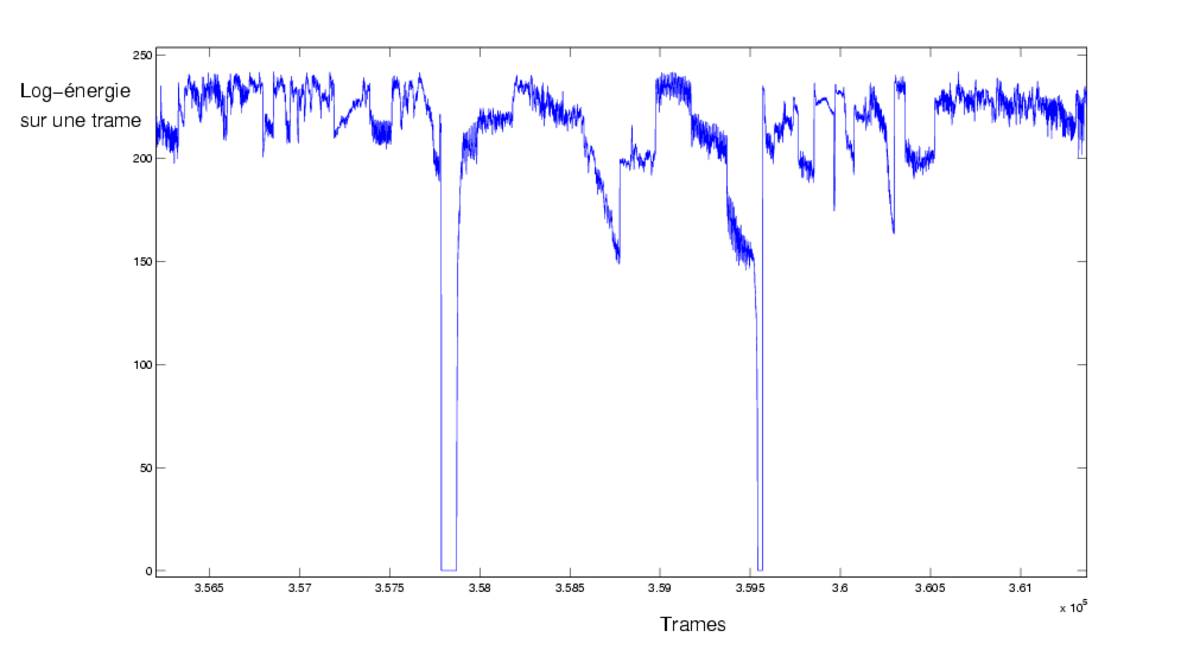
Les images monochromes de séparation sont généralement accompagnées d'instants de silence. Certains auteurs utilisent la détection de silence comme une source d'information supplémentaire pour rendre plus robuste la détection des séparations.
La détection de silence s'effectue en général à partir de l'énergie du signal audio. D'autres caractéristiques, tels le ZCR peuvent aussi être utilisées. Sur les chaînes françaises, le silence se révèle être une bonne observation, grâce à sa facilité de détection. L'énergie du signal audio tombe en effet à zéro lors des séparations entre publicités.
Logo
Certains auteurs ont remarqué que le logo de la chaîne n'était pas présent durant les publicités. La détection du logo peut donc être un indicateur intéressant.
La détection de logo est malheureusement une tâche difficile : logos semi-transparents, couleurs dynamiques, mouvement… De plus, la présence du logo n'est pas toujours systématique dans les programmes, d'où des faux positifs.
Taux d'activité
Une indication souvent utilisée est une mesure du taux d'activité : nombre de plans par minute, indication de mouvement… Les publicités possèdent en effet généralement un rythme de montage élevé, afin de capter l'attention des téléspectateurs.
Une des premières propositions est celle de Lienhart et al., qui calculent le nombre de coupures « brutales » entre deux plans, qu'ils estiment à 20,9 par minute pour les publicités et à 3,7 pour le reste. À cela s'ajoute une mesure de l'activité, à partir des changements dans les contours, détectés par une méthode de détection de contour, ainsi qu'à partir de la longueur des vecteurs de mouvement.
Cette observation est aussi sujette à de nombreuses fausses alarmes : films d'action, clips, bandes annonces…
Divers
D'autres observations peuvent aussi être utilisées : la présence de texte par une méthode de détection de texte. Cette dernière est malheureusement un processus coûteux, faisant en général appel à des techniques de morphologie mathématique, complexes, et donc peu adaptées à traiter des volumes relativement importants de vidéo. De nombreuses fausses alarmes existent aussi (génériques, bandes-annonces, journal télévisé…).
D'autres observations sont parfois évoquées : les sous-titres télétexte, la présence simultanée de musique et de parole…
Parfois mentionné, le volume sonore ne semble pas être une observation fiable. Une étude faite par l'ENST sur des chaînes françaises a montré que l'augmentation du volume existait sur seulement 50 % des séquences publicitaires, ce qui ne permet pas d'utiliser le volume comme une observation discriminante. De plus, la loi française régulant le volume sonore des publicités télévisées, par l'article 14 du décret n°92-280 du 27 mars 1992, les chaînes seraient donc en infraction si c'était effectivement le cas.
Méthodes de détection
Satterwite et Marques identifient deux types de méthode de détection : les méthodes à base d'observations et les méthodes de type reconnaissance.
Méthodes à base d'observations
Dans ce type de méthode, les auteurs choisissent un ensemble d'observations discriminantes et élaborent des algorithmes à base de règle ou des algorithmes d'apprentissage.
De simples règles sont parfois utilisées, par exemple en imposant des conditions sur la durée et la position des images monochromes. Ces méthodes font appel à beaucoup d'a priori, sont donc difficilement généralisables, et ne sont pas robustes à un changement de la structure de diffusion.
Une catégorie relativement importante de travaux consiste à réaliser un apprentissage sur les observations, en se basant en général sur une segmentation en plans effectuée au préalable. Il a ainsi été proposé d'utiliser un modèle de Markov caché à deux états, publicité et non-publicité, avec deux observations : la présence du logo et la durée des plans. Les modèles de séparateurs à vaste marge sont utilisés par Hua et al. pour classer chaque plan, à partir de nombreuses observations vidéos bas niveau mais aussi d'observations audio un peu plus sophistiquées : la présence de transitions audio et une classification en parole, musique et bruit.
Une technique de boosting contraint temporellement a aussi été proposée par Liu et al., en utilisant diverses observations audio et vidéo de bas niveau (ECR, énergie audio…) calculées sur chaque plan.
Ces techniques d'apprentissage statistique font moins d'a priori sur la structure des publicités, mais produisent de moins bons résultats que les techniques à base de règle ou de reconnaissance, principalement à cause du fait qu'il est difficile d'identifier un plan comme étant une publicité par ses seules caractéristiques sonores ou visuelles.
Méthodes de type reconnaissance
Ce type de méthode consiste à reconnaître les publicités lors de leur diffusion. Ceci nécessite la présence d'une base de publicités connues à l'avance. La détection est alors ramenée à une comparaison avec les éléments de la base.
L'intérêt d'une telle méthode est justifié par le fait que les publicités sont diffusées un grand nombre de fois, les annonceurs achetant un certain nombre de diffusions de leur publicité. Une fois qu'une publicité est dans la base, il est alors possible de détecter toutes ses rediffusions. L'autre intérêt est que la reconnaissance est une méthode assez fiable, et qui donne des résultats complémentaires par rapport aux méthodes à base d'observations.
La reconnaissance a été proposée dès les travaux de Lienhart et al. en 1997. Le principe général est de calculer une signature, ou fingerprint, sur l'image ou l'audio, et de définir ensuite une distance entre signatures pour pouvoir les comparer. C'est un principe aussi utilisé en recherche d'image par le contenu. La spécificité provient du fait que la notion de « similarité » est ici bien mieux définie : il s'agit d'une copie quasi à l'identique, abstraction faite du bruit de transmission.
Les signatures doivent donc être robustes aux bruits apparaissant dans la chaîne de transmission : variations de luminosité, de couleur, artefacts de compression… et doivent répondre à des exigences de complexité. En conséquence, les signatures proposées sont compactes et intègrent des informations considérées comme caractéristiques de l'image elle-même, et non caractéristiques d'une certaine classe d'image, comme en recherche d'image par le contenu. Les signatures ont donc un grand pouvoir discriminant.
Plusieurs définitions de signatures à partir de l'image ont été proposées : le color coherence vector, sélection et quantification des coefficients ondelettes, DCT, les moments d'ordre 1, 2 et 3 des trois canaux RVB, ou encore à partir de l'analyse en composantes principales sur les histogrammes couleurs.
Quelques travaux mentionnent aussi la possibilité d'utiliser des signatures audios, par exemple en calculant un spectrogramme sur plusieurs bandes de fréquences, ou une technique plus générique proposée par Herley.
Une des difficultés est liée à la complexité de ces méthodes lorsqu'aucune technique d'indexation de la base n'est utilisée : il faut en effet parcourir l'ensemble de la base à chaque instant pour pouvoir reconnaître un segment. La distance utilisée pour mesurer la similarité entre signatures pouvant nécessiter beaucoup de calculs, il existe un vrai problème de complexité.
Afin de remédier à ce problème, certains auteurs proposent d'utiliser des techniques de hachage perceptuel. Ceci consiste à utiliser la signature comme un index, ce qui permet alors un accès direct à la base grâce par exemple à une structure de données telle qu'une table de hachage. On s'affranchit alors de la complexité liée à une recherche séquentielle de la base.
Autres méthodes
D'autres types de méthode existent, comme l'utilisation du tatouage, qui consiste à insérer au préalable une marque dans le flux vidéo à détecter. C'est une technique robuste mais contraignante, puisqu'elle nécessite que les publicités soient tatouées avant d'être diffusées. L'utilisation du tatouage est donc en pratique restreint à une seule classe d'application : le suivi de la diffusion des publicités.
Une technique originale proposée par Poli et al. consiste à prédire les horaires de début et de fin d'émissions et leurs types, grâce à un modèle de Markov caché contextuel. Les instants de publicités peuvent alors se déduire de la structuration ainsi produite.
Difficultés
La principale difficulté vient du fait que les modes de diffusion des publicités sont différents d'un pays, voire d'une chaîne à l'autre. En conséquence, les techniques proposées sont généralement adaptées à un pays, et il semble difficile de développer une méthode générique.
De plus, il existe de réelles difficultés pour les scientifiques à disposer d'un corpus suffisamment volumineux et provenant de pays différents, ainsi que le problème récurrent de la vérité terrain. Les méthodes sont ainsi généralement validées sur des corpus relativement réduits de quelques heures. Certains travaux commencent toutefois à valider leurs résultats sur des corpus plus importants (4 jours pour Covell et al.).
Résultats
Les performances des algorithmes sont généralement évaluées par des mesures issues de la recherche d'information : le rappel r et la précision p. Si le nombre d'unités correctement classées est Nb, le nombre d'unités manquées est Nm, et le nombre d'unités fausses est Nf alors la précision et le rappel sont donnés par :


Malheureusement, il n'existe pas de consensus sur le type d'unité à choisir. La plupart des auteurs choisissent comme unité la publicité elle-même. Les mesures de précision et de rappel ont alors une interprétation intuitive, mais peu précise : on ne sait pas si la publicité est détectée dans sa totalité ou non.
La petite taille des corpus fait que les résultats sont parfois à relativiser. Shivadas et al. annoncent 96 % de rappel et 100 % de précision sur un corpus de seulement 2 heures, comportant 63 publicités. Covell et al. obtiennent, quant à eux, 95 % de rappel et 99 % de précision sur 96 heures de télévision. Ces bons résultats sont dus à des méthodes de type reconnaissance. Les méthodes basées sur des observations sont généralement moins performantes. À titre d'exemple, McGee et coll. rapportent une précision de 94 % et un rappel de 87 % sur 13 heures.
D'autres auteurs utilisent le plan comme unité. C'est une mesure qui permet une meilleure précision temporelle, mais d'interprétation délicate. Les plans pouvant être de nombre et de longueur variable. Hua et al. obtiennent 92 % en rappel et précision sur un corpus de 10 heures.
Enfin, certains auteurs utilisent l'image comme unité. L'interprétation est alors simple puisque cela devient une unité de mesure temporelle. Par exemple, Chen et al. obtiennent 94 % de rappel et 92,5 % de précision sur 7 heures.