Extensible Markup Language - Définition
La liste des auteurs de cet article est disponible ici.
Utilisations et langages dérivés
SGML était une syntaxe générique, permettant de définir des langages spécialisés, comme HTML, mais il était surtout dédié au balisage de documents. En simplifiant SGML, les concepteurs d'XML prévoyaient d'élargir l'usage des chevrons (< >) à bien d'autres emplois, comme par exemple, la programmation. Les premiers langages basés sur XML par le W3C dessinent plusieurs directions d'utilisation.
- 1999, RDF Resource Description Framework(en) « cadre de description de ressource »(fr). Ce modèle abstrait vise à définir un réseau de métadonnées adapté au web, représentable en XML.
- 1999, XSLT eXtended Stylesheet Language Transformations « langage XML de feuilles de style, transformations ». Afin d'employer XML, il faut pouvoir le transformer. James Clark avait écrit un langage équivalent pour SGML (DSSSL, 1996), avec XSLT, il propose une syntaxe XML, permettant par exemple de transformer un contenu XML vers (x)HTML, ou XSL-FO.
- 2000, XSL-FO eXtended Stylesheet Language - Formatting Object « langage XML de feuilles de style - Formatage d'objets ». XSL-FO est un langage de description de document permettant de composer un livre, ou un document PDF. C'était un complément indispensable à XML pour les industries de l'édition.
- Enfin, il fallait une nouvelle syntaxe schéma tenant compte des espaces de noms pour remplacer les DTDs (ce qui deviendra XML Schema).
Quelques mois après sa sortie, XML est donc utilisé pour encoder des données, programmer des transformations, représenter un objet imprimable, et définir le schéma d'un document XML. Ceci annonce la variété des utilisations de cette syntaxe. Quelques années après, le catalogue est beaucoup plus important, couvrant des usages comme :
- langage de balisage de documents,
- format de données,
- langage de description de format de document (DSDL),
- langage de représentation (texte, image…),
- langage de programmation,
- protocole de communication.
Ces catégories permettent une classification approximative des langages à base XML (ou acceptant une expression XML). La liste des langages plus bas repère quelques spécifications marquantes. Elles ont fait date dans le monde XML. Les succès, ou les critiques, permettent aussi de montrer à quoi XML est bon, et là où il est parfois discuté.
Balisage de document
Le balisage de document est le métier initial d'XML. Les DTD SGML publiques comme TEI et Docbook l'ont adopté. XML aurait pu permettre l'apparition de nombreux autres schémas. On assiste plutôt à l'apparition de vocabulaires spécialisés, et combinables à l'exemple de la modularisation XHTML :
- XHTML - eXtensible HyperText Markup Language, Langage de balisage hypertexte
- Docbook - documentation technique, 1991 à 1997 O'Reilly, 1998 à … OASIS, (Norman Walsh).
- TEI - Text Encoding Initiative, balisage de textes académiques, 1987, 1994, 1999, 2002, Text Encoding Initiative.
- EAD Encoded Archival Description, description archivistique, 1993, 2002, Bibliothèque du Congrès.
- NITF News Interchange Text Format, échange d'articles de presse, 2000, 2002, IPTC.
- NewsML News Markup Language, balisage de dépêche de presse, 2000, 2002, IPTC.
Format de données
XML s'est imposé comme format de référence pour l'échange de données, notamment de métadonnées. L'exemple d'un transfert d'informations entre base de données relationnelles permettra d'illustrer les avantages et limites de ce format pour cet usage.
L'exportation d'une table peut se faire en csv. Mais ce format comporte vite des limites à grande échelle (Internet). Il n'est pas auto-documenté (encodage du texte, séparateurs, ordre et nom des colonnes ?). Il demande une documentation externe rarement automatisée entre les partenaires. Que faire lorsque les tables source et destination n'ont pas des structures identiques ? Pour cette raison, on peut préférer des échanges en SQL (à la fois langage de définition de données et langage de manipulation de données). Cependant, malgré de nombreux efforts de normalisation, SQL comporte beaucoup de risques d'incompatibilité entre les implémentations [1]. XML est une solution plus robuste. On peut en constater l'efficacité sur Internet avec la syndication de contenu. Il n'y a pas d'exemple connu d'échange de métadonnées réparties sur autant de « clients » et de « serveurs ».
Verbosité ? - Comparé à l'export CSV d'une table, XML réplique le nom de la colonne pour chaque cellule (une fois pour un attribut, deux fois pour un élément). Le poids du fichier généré est supérieur à celui d'un fichier CSV. Dans des contextes où la bande passante est coûteuse (exemple : téléphonie mobile), cela n'a pas semblé poser de problème (WML), car ces répétitions se compressent très bien (zip).
Traitement lourd ? - Traiter du XML demande des bibliothèques dédiées (processeur XML). Cela n'ajoute pas vraiment du temps de développement supplémentaire, du moins pour des équipes formées. Pour des petites tâches, un parseur ligne à ligne est parfois plus simple. Mais si la donnée se destine à se complexifier, à s'échanger plus largement, il vaut mieux choisir XML dès le départ.
XML : données ou document ? - Cette section est l'occasion de marquer la distinction entre XML données et XML document. Il ne s'agit pas d'une différence dans la syntaxe, mais dans ses usages, ses outils et ses communautés d'utilisateurs. Par SGML, XML vient du document. On lui a reproché par exemple ne pas avoir (nativement) de typage fort. On rencontre un mouvement analogue mais contraire en SQL. C'est originalement un format de données, on lui demande de plus en plus de traiter du texte. (CMS LAMP). En ce qui concerne XML, cette opposition se traduit dans la direction des efforts de spécification (types de données XML Schema, XPath 2.0, XSLT 2.0) avec des réactions du monde documentaire (Relax NG).
- RDF - Resource Description Framework Réseaux de métadonnées, © 1997 à 2006 W3C.
- RSS Rich Site Summary, RDF Site Summary et Really Simple Syndication, 1999 à…, (principe plus que norme).
- Atom - syndication, 2003, IETF.
- OWL - Ontologies (W3C)
- GML - Données géographiques (Open Geospatial Consortium)
- Dublin Core - bibliographie (dublincore.org)
- MODS - bibliographie (Bibliothèque du Congrès, USA)
- METS - échange de collection de fichiers (Bibliothèque du Congrès, USA)
- BiblioML - bibliographie (Bibliothèque nationale de France)
- EbXML - commerce électronique (OASIS)
- XBRL - Données comptables
- XMI - XML Metadata Interchange
Langages de schéma
Un processus XML complet comporte une étape de validation des documents. C'est le rôle d'un schéma de définir ces règles de validité. Faut-il que ce schéma soit en XML ? La question ne se posait pas en SGML, qui connaissait surtout les DTD, une syntaxe texte. Les limites rencontrées alors concernaient surtout la documentation des éléments et attributs déclarés(en). La documentation est très importante pour la réussite d'un standard XML. Celles de Docbook ou TEI constituent des livres complets, avec même des versions imprimées.
Ces communautés ont attendu avec impatience ce que donnerait XML Schema. Les nombreux outils de documentation automatiques qui sont apparus, avec un simple jeu d'XSLT, prouvent l'intérêt d'XML comme langage de description de format de document. Cependant, pour des choses simples, XML Schema s'est avéré difficile. Est-ce l'effet de trop de concessions ? Toujours est-il que malgré le nombre d'éditeurs derrière le W3C, la communauté est très intéressée par Relax NG, de James Clark. Ce modèle accepte une syntaxe XML, et depuis 2003, propose aussi une forme compacte, textuelle, qui n'est pas XML.
Autrement dit, il n'y a plus de réponse unique. Un schéma XML peut se définir dans un vocabulaire XML, ou autrement. L'évolution actuelle est de pouvoir combiner plusieurs langages de schémas, notamment le typage fort d'XML Schema, avec des motifs XPath pour Schematron, dans du Relax NG.
- DTD Document Type Definition « définition de type de document », ISO.
- XML Schema langage de Schéma XML, W3C, 2001.
- Relax NG, DSDL acceptant une forme XML et une syntaxe compacte, ISO , 2001.
- Schematron, validation par motifs, ISO, 2001.
Langages de représentation
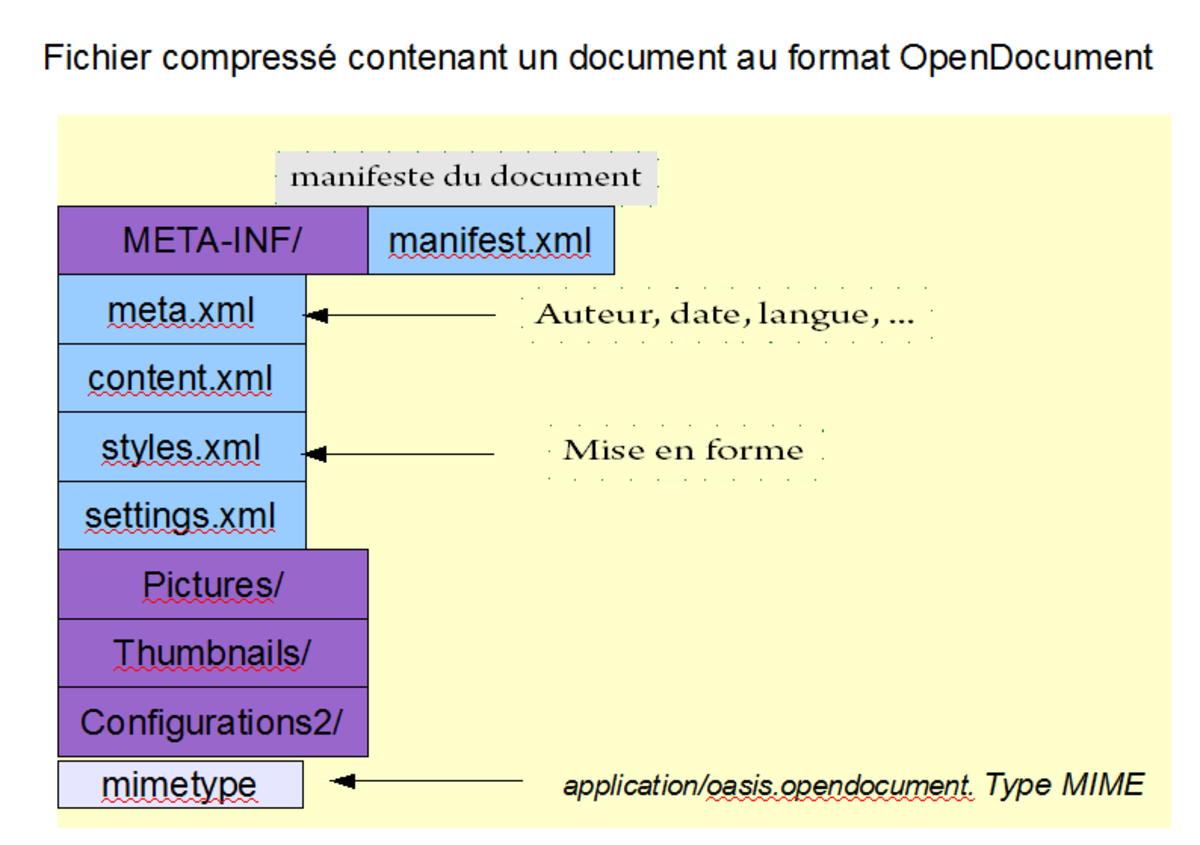
On vante souvent XML pour sa faculté de séparer contenu, présentation et traitement. Attention, XML rend cette séparation possible, mais il n'interdit pas de tout mélanger, comme dans certaines pages XHTML sur Internet. En tous cas, ce format extensible a prouvé qu'il pouvait conserver la présentation des documents pour les applications les plus exigeantes. La variété des applications l'utilisant en est la preuve.
- OpenDocument - tous les documents bureautiques, OpenOffice.org, 2001.
- Word - le format natif de Microsoft Word (traitement de texte) est en XML depuis sa version 2003.
- XSL-FO - eXtensible Stylesheet Language - Formatting Objects, langage extensible de stylage - formatage d'objets, W3C, 2001.
- SVG - Scalable Vector Graphics, graphiques vectoriels 2D, W3C, 2003.
- MathML - formules mathématiques, W3C, 1999, 2001, 2003.
- SMIL - Synchronized Multimedia Integration Language, Intégration multimédia, W3C, 1998, 2005.
- X3D - 3D multimédia, consortium Web3D.
Langages de programmation
Dans de nombreuses applications, il est parfois pratique de développer un langage spécialisé, à usage local. Avec un schéma, un dialecte XML dispose d'une grammaire (un peu comme BNF). En guise de compilateur, il suffit par exemple d'une transformation XSLT qui génère du code Java, comme pour une bibliothèque de balises (taglibs). Cet exemple montre comment la syntaxe XML permet de définir des langages de programmation.
En théorie, la structure en arbre d'XML permet de représenter la hiérarchie d'un programme objets, ou l'imbrication des instructions d'un langage impératif. En pratique, les boucles sont le cas limite à partir duquel XML devient trop verbeux. Par contre, cette écriture est remarquablement adaptée aux syntaxes déclaratives (configuration, définition d'interface), et même, popularise les algorithmes fonctionnels (XSLT, logique d'une application web).
Il en résulte que l'on trouve de plus en plus d'XML dans les logiciels. Dans certains frameworks de développement web, il est possible de monter une application complète et complexe, en n'éditant que du XML.
- XSLT - Extended Stylesheet Language Transformations, transformation de document XML, W3C, 1999.
- XQuery - requête et transformation XML, W3C, 2005.
- ANT - scripts de compilation, ASF.
- Servlet - serveur d'application Java, configuration et logique fonctionnelle, Sun Microsystems.
- Log4j - log for Java, configuration d'une bibliothèque d'historique, 1996, © 1999-2006, ASF.
- UIML - User Interface Markup Language, définition d'interface, OASIS, 1997.
- XUL - XML-based User interface Language, définition d'interface, Mozilla, 2000.
- XAML - définition d'interface, Windows Vista, 2006.
- MXML, Flex - définition d'interface, Macromedia.
- Apache XSP - eXtensible Server Pages - génération de documents XML côté serveur.
Protocoles d'échanges
Un protocole spécifie l'échange de contenus et d'instructions, entre un client et un serveur. HTTP est un modèle de protocole (qui n'est pas XML mais textuel). XML permet de baliser des contenus et d'écrire des instructions de programmation. L'universalisation de la connexion HTTP comme des processeurs XML explique pourquoi XML devient une solution courante pour créer un nouveau protocole.
- XForms - formulaires web (W3C)
- OAI - Open Archive Initiative Protocole Archives ouvertes, 2000, 2002 (OAI)
- SOAP - RPC par HTTP (W3C)
- WSDL - Services web (W3C)
- WebDAV - Lecture/Écriture distante par HTTP (IETF)
- Jabber/XMPP - Messagerie instantanée et présence, multimédia (IETF)
Langages associés
Les langages associés à XML sont des syntaxes qui ne sont pas en XML mais très attachées à XML. CSS illustrera bien la notion. Il peut être contenu dans un attribut (@xhtml:style), dans un élément (
- CSS (Cascading Style Sheet)
- DTD (Document Type Definition)
- Espace de noms (Namespace)
- SGML
- XPath et XQuery, langages de requête. NB: XQuery possède aussi une syntaxe XML, XQueryX.
Conclusion, étape suivante ?
En 2001, on demandait à James Clark, un expert XML et SGML, What's the next step for XML? « Quelle est l'étape suivante pour XML » ? Il répondit d'abord que cela revenait à demander quelle est l'étape suivante pour le texte ASCII ou pour les fichiers à lignes délimitées. XML est en effet devenu un format aussi universel qu'Unicode pour structurer des contenus, comme un esperanto de l'informatique.
Qu'un arbre XML permette de représenter beaucoup de choses ne signifie pas que ce soit toujours la forme la plus adaptée, chaque utilisation a ses cas limites. Ainsi l'arbre bute sur un motif simple : l'intersection. Considérez ce texte tuilé : en gras et en italique. Le et appartient à deux zones, chose simulable mais pas native dans un arbre. On peut en faire une représentation XHTML comme ceci en gras et en italique, dont on voit d'ailleurs qu'elle n'est pas unique, car la notion d'intersection est perdue. Ce détail se démultiplie dans les applications WYSIWYG qui produisent du XML (traitement de texte, SVG), rendant la source générée de moins en moins lisible par un humain. Ce détail amènera peut-être un nouveau format.
Selon James Clark en 2001, la nouveauté ne viendrait plus du format, mais de l'intégration applicative pour le traiter, c'est encore vrai en 2007.