Statistiques - Définition
La liste des auteurs de cet article est disponible ici.
La démarche statistique
Recueil des données
L'enquête statistique est toujours précédée d'une phase où sont déterminés les différents caractères à étudier.
L'étape suivante consiste à choisir la population à étudier. Il se pose alors le problème de l'échantillonnage : choix de la population à sonder (au sens large : cela peut être un sondage d'opinion en interrogeant des humains, ou bien le ramassage de roches pour déterminer la nature d'un sol en géologie), la taille de la population et sa représentativité.
- Voir article détaillé : Plan d'expérience
Que ce soit pour un recueil total (recensement) ou partiel (sondage), des protocoles sont à mettre en place pour éviter les erreurs de mesures qu'elles soient accidentelles ou répétitives (biais).
- Voir articles détaillés : Erreur (métrologie), Erreur statistique.
Le pré traitement des données est extrêmement important, en effet, une transformation des données initiales (un passage au logarithme, par exemple), peuvent considérablement faciliter les traitements statistiques suivants.
Traitement des données
- Voir article détaillé : statistique descriptive
Le résultat de l'enquête statistique est une série de chiffres (tailles, salaires) ou de données qualitatives (langues parlées, marques préférées). Pour pouvoir les exploiter, il va être nécessaire d'en faire un classement et un résumé visuel ou numérique. Il sera parfois nécessaire d'opérer une compression de données. C'est le travail de la statistique descriptive. Il sera différent selon que l'étude porte sur une seule variable ou sur plusieurs variables.
Étude d'une seule variable
Le regroupement des données, le calcul des effectifs, la construction de graphiques permet un premier résumé visuel du caractère statistique étudié. Dans le cas d'un caractère quantitatif continu, l'histogramme en est la représentation graphique la plus courante.
- Voir article détaillé : Représentations graphiques de données statistiques
Les valeurs numériques d'un caractère statistique se répartissent dans

- Voir articles détaillés : critères de position, critères de dispersion.
On peut aussi chercher à comparer deux populations. On s'intéressera alors plus particulièrement à leurs critères de position, de dispersion, à leur boîte à moustaches ou à l'analyse de la variance.
Étude de plusieurs variables
Les moyens informatiques permettent aujourd'hui d'étudier plusieurs variables simultanément. Le cas de deux variables va donner lieu à la création d'un nuage de points, d'une étude de corrélation (mathématiques) éventuelle entre les deux phénomènes ou étude d'une régression linéaire .
Mais on peut rencontrer des études sur plus de deux variables : c'est l'analyse multidimensionnelle dans laquelle on va trouver l'analyse en composantes principales, l'analyse en composantes indépendantes, la régression linéaire multiple et le data mining. Aujourd'hui, le data mining (appelé aussi knowledge discovery) s'appuie sur la statistique pour découvrir des relations entre les variables de très vastes bases de données. Les avancées technologiques (augmentation de la fréquence des capteurs disponibles, des moyens de stockage, et de la puissance de calcul) donnent au data mining un vrai intérêt.
Interprétation et analyse des données
L'inférence statistique a pour but de faire émerger des propriétés d'un ensemble de variables connues uniquement à travers quelques unes de ses réalisations (qui constituent un échantillon de données).
Elle s'appuie sur les résultats de la statistique mathématique, qui applique des calculs mathématiques rigoureux concernant la théorie des probabilités et la théorie de l'information aux situations où on n'observe que quelques réalisations (expérimentations) du phénomène à étudier.
Sans la statistique mathématique, un calcul sur des données (par exemple une moyenne), n'est qu'un indicateur. C'est la statistique mathématique qui lui donne le statut d'estimateur dont on maîtrise le biais, l'incertitude et autres caractéristiques statistiques. On cherche en général à ce que l'estimateur soit sans biais, convergeant et efficace.
On peut aussi émettre des hypothèses sur la loi générant le phénomène général, par exemple « la taille des enfants de 10 ans en France suit-elle une loi gaussienne ? ». L'étude de l'échantillon va alors valider ou non cette hypothèse : c'est ce qu'on appelle les tests d'hypothèses. Les tests d'hypothèses permettent de quantifier la probabilité avec laquelle des variables (connues seulement à partir d'un échantillon) vérifient une propriété donnée.
Enfin, on peut chercher à modéliser un phénomène a posteriori. La modélisation statistique doit être différenciée de la modélisation physique. Dans le second cas des physiciens (c'est aussi vrai pour des chimistes, biologistes, ou tout autre scientifique), cherchent à construire un modèle explicatif d'un phénomène, qui est soutenu par une théorie plus générale décrivant comment les phénomènes ont lieu en exploitant le principe de causalité. Dans le cas de la modélisation statistique, le modèle va être construit à partir des données disponibles, sans aucun a priori sur les mécanismes entrant en jeux. Ce type de modélisation s'appelle aussi modélisation empirique. Compléter une modélisation statistique par des équations physiques (souvent intégrées dans les pré traitements des données) est toujours positif.
Un modèle est avant tout un moyen de relier des variables à expliquer Y à des variables explicatives X, par une relation fonctionnelle :
- Y = F(X)
Les modèles statistiques peuvent être regroupés en grandes familles (suivant la forme de la fonction F):
- les modèles linéaires ;
- les modèles non linéaires ;
- les modèles non paramétriques.
Les modèles bayésiens (du nom de Bayes) peuvent être utilisés dans les trois catégories.
Statistique mathématique
- Voir article détaillé : statistique mathématique
Cette branche des mathématiques, très liée aux probabilités, est indispensable pour valider les hypothèses ou les modèles élaborés dans la statistique inférentielle. La théorie mathématiques des probabilités formalise les phénomènes aléatoires. Les statistiques mathématiques se consacrent à l'étude de phénomènes aléatoires que l'on connaît via certaines de ses réalisations.
Par exemple, pour une partie de dés à six faces :
- le point de vue probabiliste est de formaliser un tel jeu par une distribution de probabilité
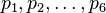
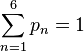
- une fois cela fixé, les statistiques s'intéressent alors à ce genre de question : « Si au bout de 100 parties, chaque face n a été tirée fn fois, puis-je avoir une idée de la valeur des probabilités


Une fois la règle établie, elle peut être utilisée en statistique inférentielle.
Statistique en sciences sociales
Les statistiques sont utilisées dans la plupart des sciences sociales. Elles présentent une méthodologie commune avec toutefois certaines spécificités selon la complexité de l'objet d'étude
En sociologie
L'apport des méthodes statistiques permet au sociologue l'utilisation de méthode quantitative lui permettant de déterminer des sociostyles.
Le problème majeur est pour le chercheur de définir des unités comparables (style de vie, tranche de revenus, opinions politiques etc ...).
Le sociologue réussit ainsi à déterminer des nuages de points correspondant à des axes comportementaux qui définissent l'évolution des différents groupes sociaux vers tel type de comportement (achat de tel ou tel produit, vote pour tel ou tel candidat à une élection).

















































