Méthode des moindres carrés - Définition
La liste des auteurs de cet article est disponible ici.
Formalisme
Deux exemples simples
Moyenne d'une série de mesures indépendantes
L'exemple le plus simple d'ajustement par la méthode des moindres carrés est probablement le calcul de la moyenne m d'un ensemble de mesures indépendantes (yi)i = 1..N entachées d'erreurs gaussiennes. Autrement dit, on veut estimer m dans la relation

pour i = 1,..,N et où

La prescription des moindres carrés revient à minimiser la quantité :

où les



La quantité χ2(m), ou somme des carrés des résidus, est une forme quadratique définie positive. Son minimum se calcule par différenciation : gradχ2(m) = 0. Cela donne la formule classique :

Autrement dit, l'estimateur par moindres carrés de la moyenne m d'une série de mesures entachées d'erreurs gaussiennes (connues) est leur moyenne pesée (ou pondérée), c'est-à-dire leur moyenne empirique dans laquelle chaque mesure est pondérée par l'inverse du carré de son incertitude. Le Théorème de Gauss-Markov garantit qu'il s'agit du meilleur estimateur linéaire non-biaisé de m.
La moyenne estimée m fluctue en fonction des séries de mesures yi effectuées. Comme chaque mesure est affectée d'une erreur aléatoire, on conçoit que la moyenne d'une première série de N mesures diffèrera de la moyenne d'une seconde série de N mesures, même si celles-ci sont réalisées dans des conditions identiques. Il importe de pouvoir quantifier l'amplitude de telles fluctuations, car cela détermine la precision de la détermination de la moyenne m. Chaque mesure yi peut être considérée comme une réalisation d'une variable aléatoire Yi, de moyenne


L'écart-type des fluctuations de M est donné par (combinaison linéaire de variables aléatoires indépendantes):

Sans grande surprise, la précision de la moyenne d'une série de N mesures est donc déterminée par le nombre de mesures, et la précision de chacune de ces mesures. Dans le cas où chaque mesure est affectée de la même incertitude σi = σ la formule précédente se simplifie en :

La précision de la moyenne s'accroit donc comme la racine carrée du nombre de mesures. Par exemple, pour doubler la précision, il faut quatre fois plus de données ; pour la multiplier par 10, il faut 100 fois plus de données.
Régression linéaire
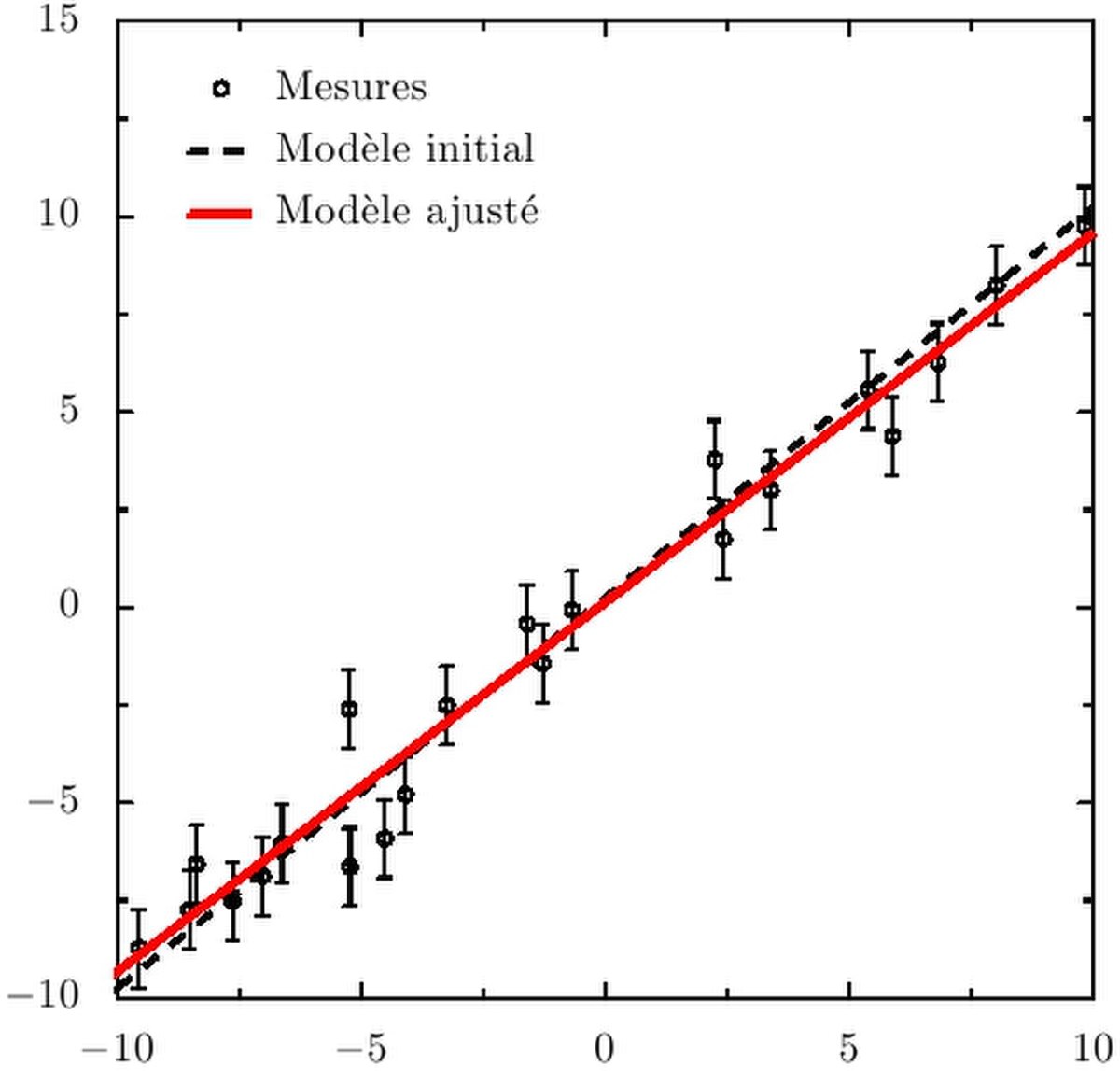
Un autre exemple est l'ajustement d'une loi linéaire du type


où les vecteurs




L'utilisation de la régression linéaire se rencontre par exemple lorsque l'on veut calibrer un appareil de mesure simple (ampèremètre, thermomètre) dont le fonctionnement est linéaire. y est alors la mesure instrumentale (déviation d'une aiguille, nombre de pas d'un convertisseur analogique-numérique, ...) et x la grandeur physique qu'est censé mesurer l'appareil, généralement mieux connue, si l'on utilise une source de calibration fiable. La méthode des moindres carrés permet alors de mesurer la loi de calibration de l'appareil, d'estimer l'adéquation de cette loi aux mesures de calibration (i.e. dans le cas présent, la linéarité de l'appareil) et de propager les erreurs de calibration aux futures mesures effectuées avec l'appareil calibré. En général, les erreurs (et les corrélations) portant sur les mesures yi et les mesures xi doivent être prises en compte. Ce cas sera traité dans la section suivante.
La prescription des moindres carrés s'écrit pour ce type de modèle:

Le minimum de cette somme des carrés pondérés est atteint pour gradχ2 = 0, ce qui donne:

ou, plus explicitement:

Là encore, il s'agit d'une estimation par moindres carrés généralisée ou pondérés. La détermination des paramètres "optimaux" (au sens des moindres carrés) α et β se ramène donc à la résolution d'un système d'équations linéaires. Il s'agit là d'une propriété très intéressante, liée au fait que le modèle lui-même est linéaire. On parle d'ajustement ou de régression linéaire. Dans le cas général, la détermination du minimum du χ2 est un problème plus compliqué, et généralement coûteux en temps de calcul (cf. sections suivantes).
La valeur des paramètres αmin et βmin dépend des mesures yi réalisées. Comme ces mesures sont entachées d'erreur, on conçoit bien que si l'on répète M fois les N mesures de calibration, et que l'on réalise à l'issue de chaque série l'ajustement décrit plus haut, on obtiendra M valeurs numériquement différentes de αmin et βmin. Les paramètres de l'ajustement peuvent donc être considérés comme des variables aléatoires, dont la loi est fonction du modèle ajusté et de la loi des yi.
En particulier, l'espérance du vecteur (αmin;βmin) est le vecteur des vraies valeurs des paramètres: l'estimation est donc sans-biais. Qui plus est, on montre que la dispersion qui affecte les valeurs de αmin et βmin dépend du nombre de points de mesure, N, et de la dispersion qui affecte les mesures (moins les mesures sont précises, plus αmin et βmin fluctueront). Par ailleurs, αmin et βmin ne sont généralement pas des variables indépendantes. Elles sont généralement corrélées, et leur corrélation dépend du modèle ajusté (nous avons supposé les yi indépendants).
Ajustement d'un modèle linéaire quelconque
Un modèle y = f(x;θ) est linéaire si sa dépendance en θ est linéaire. Un tel modèle s'écrit :

où les φk sont n fonctions quelconques de la variable x. Un tel cas est très courant en pratique : les deux modèles étudiés plus haut sont linéaires. Plus généralement tout modèle polynomial est linéaire, avec φk(x) = xk. Enfin, de très nombreux modèles utilisés en sciences expérimentales sont des développements sur des bases fonctionnelles classiques (splines, base de Fourier, bases d'ondelettes etc.)
Si nous disposons de N mesures, (xi,yi,σi), le χ2 peut être écrit sous la forme :

Nous pouvons exploiter la linéarité du modèle pour exprimer le χ2 sous une forme matricielle plus simple. En effet, en définissant :



et

on montre facilement que le χ2 s'écrit sous la forme:

La matrice J est appelée matrice jacobienne du problème. C'est une matrice rectangulaire, de dimension N x n, avec généralement N >> n. Elle contient les valeurs des fonctions de base φk pour chaque point de mesure. La matrice diagonale W est appelée matrice des poids. C'est l'inverse de la matrice de covariance des yi. On montre que si les yi sont corrélés, la relation ci-dessus est toujours valable. W n'est simplement plus diagonale, car les covariances entre les yi ne sont plus nulles.
En différentiant la relation ci-dessus par rapport à chaque θk, on obtient :

et le minimum du χ2 est donc atteint pour θmin égal à :

On retrouve la propriété remarquable des problèmes linéaires, qui est que le modèle optimal peut-être obtenu en une seule operation, à savoir la résolution d'un système

Équations normales
Dans le cas d'équations linéaires surdéterminées à coefficients constants, il existe une solution simple. Si nous disposons d'équations expérimentales surdéterminées sous la forme

nous allons représenter l'erreur commise par un vecteur résidu

La norme du résidu



où AT est la transposée de A
Ajustement de modèles non-linéaires
Dans de nombreux cas, la dépendance du modèle en θ est non-linéaire. Par exemple, si f(x;θ) = f(x;(A,ω,φ)) = Acos(ωx + φ), ou f(x;θ) = f(x;τ) = exp( − x / τ). Dans ce cas, le formalisme décrit à la section précédente ne peut pas être appliqué directement. L'approche généralement employée consiste alors à partir d'une estimation de la solution, à linéariser le χ2 en ce point, résoudre le problème linéarisé, puis itérer. Cette approche est équivalente à l'algorithme de minimisation de Gauss-Newton. D'autres techniques de minimisation existent. Certaines, comme l'algorithme de Levenberg-Marquardt, sont des raffinements de l'algorithme de Gauss-Newton. D'autres sont applicables lorsque les dérivées du χ2 sont difficiles ou coûteuses à calculer.
Une des difficultés des problèmes de moindres carrés non-linéaires est l'existence fréquente de plusieurs minima locaux. Une exploration systématique de l'espace des paramètres peut alors se révéler nécessaire.

















































